
【论文阅读笔记】Towards Evaluating the Robustness of Neural Networks
2017年的攻击文章,目标是当时防御性较高的防御性蒸馏模型,属于图像分类模型。结果是成功令其鲁棒性下降。文章最后的结论是,做防御的人应该用较先进的攻击手段测试自己的模型,同时应该注意防御对抗样本的迁移特性,即在其他弱模型上生成样本后在目标模型上测试的行为。
警告!本文为简读,大量省略了原文内容,只留下了我关注的细节。
引言防御性模型蒸馏(Defensive distillation)是近年来抵御对抗样本攻击的最有效方法之一。防御性模型蒸馏应用于前馈神经网络,只需一次重训练,就能将攻击成功率从95%降至0.5%。
目前有两种衡量神经网络鲁棒性的方法,一是试图证明一个下界,二是攻击模型,试图展

【论文阅读笔记】Fuzzing: A Survey
2018年CyberSecurity收录的一篇关于软件测试中模糊测试的综述。作者来自清华大学。文章名越短越霸气。
警告!本文在写作过程中大量使用了谷歌翻译。
一、引言模糊测试几乎不需要了解目标,并且可以轻松扩展到大型应用程序,因此已成为最受欢迎的漏洞发现解决方案
模糊的随机性和盲目性导致发现错误的效率低下
反馈驱动的模糊模式(feedback-driven fuzzing mode)和遗传算法(genetic algorithms)的结合提供了更灵活和可自定义的模糊框架,并使模糊过程更加智能和高效。
二、背景
1.静态分析静态分析(Static Analysis)是对在没有实际执行程序的情
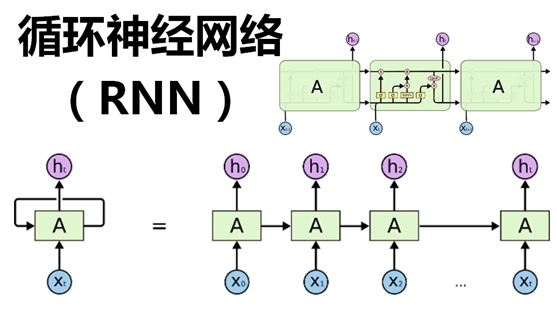
【学习笔记】LSTM网络结构简介与对应的keras实现
从理论和代码两个层面介绍了LSTM网络。
一、理论来一波循环神经网络(Recurrent Neural Network,RNN)是一类有短期记忆能力的神经网络。在循环神经网络中,神经元不但可以接受其他神经元的信息,也可以接受自身的信息,形成具有环路的网络结构。
长短期记忆网络(Long Short-Term Memory Network,LSTM)[Gers et al.,2000; Hochreiter et al., 1997] 是循环神经网络的一个变体,可以有效地解决简单循环神经网络的梯度爆炸或消失问题。
LSTM 网络引入一个新的内部状态(internal state) $\bol

【论文阅读笔记】Deep Text Classification Can be Fooled
国内人民大学的一篇论文,被IJCAI-2018接收。主要研究文本领域的对抗样本生成,被测模型是文本分类领域的模型。
1. 引言当前的对抗样本生成领域集中在图像的扰动和生成,文本领域少有涉及。
文本对抗样本应当满足:
使模型分类错误
与原样本相比,扰动难以察觉
实用性,即文本含义不发生改变
本文采用的生成思路:
三种扰动策略:插入、修改和删除
自然语言水印
白盒+黑盒
自然语言水印(Natural Language Watermarking)是通过修改文本元素(如线条,文字或字符)的外观,或更改文本格式或字体(例如,通过-文字中的单词和字母间距)来嵌入信息的技术。
2. 目标模型和数

【学习笔记】机器学习中处理文本数据的常用方法
总结词袋模型、Tf-idf等文本特征提取方法
一、词袋模型文本数据通常被表示为由字符组成的字符串。我们需要先处理数据,然后才能对其应用机器学习算法。
在文本分析的语境中,数据集通常被称为语料库(corpus),每个由单个文本表示的数据点被称为文档(document)。
最简单的处理方法,是只计算语料库中每个单词在每个文本中的出现频次。这种文本处理模型称之为词袋模型。
不考虑词语出现的顺序,每个出现过的词汇单独作为一列特征,这些不重复的特征词汇集合为词表。
每一个文本都可以在很长的词表上统计出一个很多列的特征向量。如果每个文本都出现的词汇,一般被标记为停用词不计入特征向量。
为了搞清楚词袋模型,
【经验分享】IMDb数据集的预处理
IMDb从官网下载与从keras直接调用的处理方法是不同的。
一、IMDb数据集的处理方法1. 官网下载法import pandas as pd
import numpy as np
from sklearn.datasets import load_files
!wget http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
!tar -zxvf aclImdb_v1.tar.gz
!ls
对于 v1.0 版数据,其训练集大小是 75 000,而不是 25 000,因为其中还包含 50 000 个用于无监督学习的无标

【经验分享】停电了怎么办?Python获取Windows电源连接信息
一旦停电,就令笔记本电脑发出响声、发送信息……。看似简单的功能,该如何利用Python实现呢?
采用笔记本电脑办公的好处是不必害怕突然停电。然而笔记本电脑不可能使用电池工作太久,此时必须尽快通知管理人员,恢复供电。
看似简单的功能,只需在Windows中注册一个HANDLE,负责接收电源适配器更改这一事件即可。但是本人没有Windows编程和系统编程的经验,只对Python熟悉。如何实现这一功能?
废话不多说,下面是代码。
import win32con
import win32api
import win32gui
import time
from ctypes import POINTER

【经验分享】TensorFlow模型训练和保存
使用LSTM训练最简单的IMDB影评分类任务,总结文本分类任务常见流程。
1. 模型训练和保存1.1 训练结束时保存训练模型,使用fit函数。fit函数的参数如下。
fit(
x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None,
validation_split=0.0, validation_data=None, shuffle=True, class_weight=None,
sample_weight=None, initial_epoch=0, steps_per_epoch=
【学习笔记】使用LSTM训练imdb情感分类模型
使用LSTM训练最简单的IMDB影评分类任务,总结文本分类任务常见流程。
1. 查看数据集1.1 官网上的数据集压缩包从IMDB官网上下载的数据集,是一个压缩包aclImdb_v1.tar.gz。解压后的目录如下:
test
train
imdb.vocab
imdbEr.txt
README
其内部不仅有完整的影评文件,还包含该影评的链接等信息。
1.2 keras自带的数据集keras里的IMDB影评数据集,内部结构分为两个部分:影评部分和情感标签部分,也就是数据集的X和y部分。
X部分的每条影评都被编码为一个整数列表。另外,每个单词的在单词表中的编码越小,代表在影评中出现频率越高。这

【论文阅读笔记】Adversarial Attacks on Deep Learning Models in Natural Language Processing: A Survey
本文总结了常见的nlp领域的对抗样本生成及攻击方法。
翻译腔预警!长文预警!
一、Introduction为代表的神经网络在最近几年取得了较大的成功。然而先前的研究表明,DNN等深度学习模型容易受到精心构建的对抗样本的攻击,这些攻击算法在原有样本基础上产生一些不可察觉的扰动,欺骗DNN给出错误的预测。
此类对抗样本攻击手段广泛应用于图像识别,图像分类任务等,但是此类攻击手段在自然语言处理nlp任务中表现不佳,究其原因是图像与文本之间的内在差异,使得图像识别任务中的攻击方法无法直接使用于nlp领域。
目前针对深度学习系统的对抗样本研究有以下三个角度:第一,通过给数据集添加无法被人类察觉的扰动来欺

【论文阅读笔记】 Fuzz Testing based Data Augmentation to Improve Robustness of Deep Neural Networks
通过模糊测试的方法进行数据增强,数据增强新思路。新加坡国立大学作品,被ICSE’2020接收。
内容概要
增强DNN的训练数据,从而增强其鲁棒性
将DNN数据扩充问题视为优化问题
使用遗传搜索来生成最合适的输入数据变体,用于训练DNN
学习识别跳过增强来加速训练
improve the robust accuracy of the DNN
reduce the average DNN training time by 25%, while still improving robust accuracy
引言过拟合产生的问题:
泛化性降低,测试集效果差;
鲁棒性不足,不能抵御样本微小扰动


Datawhale——SVHN——Task05:模型集成
三个臭皮匠,顶个诸葛亮。
1. 集成学习集成学习的一般结构,是首先产生一组“个体学习器”,再用某种策略将其结合起来。类似于“三个臭皮匠,顶个诸葛亮”的思想。
如果自己的个体学习器性能不是很令人满意,使用集成学习将能够提升一定的性能,集成学习器一般都能够获得比个体学习器要好的效果。
集成学习效果要提升,要尽可能满足两个条件:
个体学习器性能不太差;
个体学习器之间不能太相似,结构、所用数据差异越大越好。
可以证明,如果个体学习器之间的决策误差不存在关联,决策相互独立,那么随着个体学习器数量的增多,集成学习器的错误率将指数下降。
根据个体学习器的生成方式,目前的集成学习方法分成两大类:
个

numpy拼合数组方法大全
numpy的一大特色就是其内部的矩阵向量运算。矩阵之间的拼接方法,你掌握多少?
1. append拼接我们都知道对于Python原生列表list来说,append是最方便的添加元素的方法,一句list.append(elem)就能在列表最后添加一个元素。
在numpy中,append也是一个直观且好用的方法,np.append(A,B)能够直接拼合两个ndarray数组。
首先我们新建两个三维数组,一个全为零,一个全为一。
C = np.zeros((2,2,2))
D = np.ones((2,2,2))
print("C: ", C, C.shape)
print(&q

移动硬盘文件或目录损坏且无法读取解决方法
问题描述:家里的移动硬盘寿命已有4年之久,里面存储了200多G的学习资料(字面意思)。今天我将其插在系统为win10的电脑上,却出现了以下情况:
硬盘通电指示灯亮;
右下角托盘区域出现usb插入提示,并可以点击“安全删除硬件”;
在“我的电脑”界面,显示“本地磁盘 D:”,但是双击之后出现错误“文件或目录损坏且无法读取”。
重启电脑、重新插拔、更换另一台win7系统的电脑,都是该状况。至此基本确定是移动硬盘本身的问题。
硬盘参数:
黑甲虫 640G 移动机械硬盘
磁盘格式为NTFS
使用4年有余
之前出现过数据丢失的状况,转移敏感数据之后,在该盘中只留有非敏感的学习资料,约280G
查阅
numpy中delete的使用方法
本文将介绍np.delete中的参数及使用方法
Python中列表元素删除在列表中删除元素,我们可以:
list_a = [1,2,3,4,5]
list_a.pop(-1)
print(list_a) # [1,2,3,4]
del list_a[0]
print(list_a) # [2,3,4]
del list[1:]
print(list_a) # [2]
在numpy的ndarray中删除元素numpy中的数组ndarray是定长数组,对ndarray的处理不像对python中列表的处理那么方便。想要删除ndarray中的元素,我们往往只能退而求其次,返回一个没有对应元素的副
Datawhale——SVHN——Task02:数据扩增
训练模型第一步、数据读取和扩增!
数据读取图像领域的数据读取方法,使用Pillow或者OpenCV内置的函数即可。
数据扩增在读取图像时,还可以对原始图像添加扰动等,这就启发我们一件事:是不是对原数据增加一些扰动,就可以使其变成新的数据呢?
下面介绍利用该思想的数据扩增环节。
1. 数据扩增为什么会有用数据扩增的最常见作用,是增加数据集,用以缓解样本量不足导致的模型过拟合现象,从而提升模型的泛化性能。
究其本质,还是扩展数据集的多样性。
试想一下,我们如果想要试图训练一个完美模型,必然要利用完美的架构+完美的训练集,这个完美的训练集必然要覆盖到样本空间的方方面面。
我们当然不可能真的搞到无限多
如何评价推荐系统以及其他智能系统
看到一篇介绍推荐系统的评价方法与指标的文章,刚好本课题组也有个同学在做推荐系统相关的课题,并且该文章的评价指标部分对我目前的课题有启发作用,因此转载。
如何评价推荐系统以及其他智能系统1. 评价推荐系统评测一个推荐系统时,需要考虑用户、物品提供商、推荐系统提供网站的利益,一个好的推荐系统是能够令三方共赢的系统。比如弹窗广告就不是一个好的推荐系统。
1.1 评测实验方法1.1.1 离线实验(offline experiment)离线实验的方法的步骤如下:
a)通过日志系统获得用户行为数据,并按照一定格式生成一个标准的数据集;b)将数据集按照一定的规则分成训练集和测试集;c)在训练集上训练用户兴趣