
【学习笔记】Docker综合实践
Datawhale Docker学习笔记第六篇
在没有学习docker之前,部署项目都是直接启动文件,比如java项目就是java –jar xxxx.jar的方式,python项目就是python xxxx.py。如果采用docker的方式去部署这些项目,一般有两种方式,以jar包项目为例
方式一、挂载部署这种方式类似于常规部署,通过数据卷的方式将宿主机的jar包挂载到容器中,然后执行jar包的jdk选择容器中的而非采用本地的。
将jar包上传到服务器的指定目录,比如/root/docker/jar。
通过docker pull openjdk:8命令获取镜像
编写docker
【学习笔记】Docker Compose
Datawhale Docker学习笔记第五篇
什么是docker compose要实现一个 Web 项目,除了 Web 服务容器本身,往往还需要再加上后端的数据库服务容器,甚至还包括负载均衡容器等,这些需要多个容器相互配合来完成。
Docker Compose 允许用户通过一个单独的 docker-compose.yml 模板文件(YAML 格式)来定义一组相关联的应用容器为一个项目(project)。
下面是一个 docker-compose.yml 示例:
里面多了image、ports、networks等标签。
如何使用docker compose在Compose 中有两个重要的概念

央行工作论文读后感
央行(中国人民银行)在2021年3月26日发表了一篇工作论文《关于我国人口转型的认识和应对之策》。论文一经发表便引起了全网的大讨论,新浪微博上的相关点击量达到3.2亿次。然而网络上的消息难免囿于其碎片话叙事风格,使人产生偏见。因此笔者抱着批判性学习的心态,拜读了该篇论文,并试图梳理主要内容,最后就相关观点提出自己的评论。
声明:本文并非学术文章,而是代表个人见解的社会评论;针对的也仅限于该篇文章,而不能涵盖文章所涉及的所有相关议题。本文写作目的仅出于学习和交流。本文作者并非研究人口与社会问题的专业人士,因此观点未免存在疏漏和幼稚之处,望读者海涵。
这篇工作论文的四名作者均是中国人民银行下属研究
【学习笔记】Docker网络
Datawhale Docker学习笔记第四篇
Docker 基础网络介绍外部访问容器容器中可以运行一些网络应用,要让外部也可以访问这些应用,可以通过-P或-p参数来指定端口映射。
当使用-P标记时,Docker会随机映射一个端口到内部容器开放的网络端口。 使用docker container ls可以看到,本地主机的 32768 被映射到了容器的 80 端口。此时访问本机的 32768 端口即可访问容器内 NGINX 默认页面。
$ docker run -d -P nginx:alpine
$ docker container ls -l
CONTAINER ID IMAG
【学习笔记】Docker数据管理、数据卷和挂载主机目录
Datawhale Docker学习笔记第三篇
数据卷
创建数据卷docker volume create datawhale
查看所有的数据卷docker volume ls
启动一个挂载数据卷的容器
在用 docker run 命令的时候,使用 —mount 标记来将数据卷挂载到容器里。在一次 docker run 中可以挂载多个 数据卷。
查看数据卷的具体信息
在主机里使用以下命令可以查看 web 容器的信息
docker inspect web
删除数据卷
docker volume rm datawhale #datawhale为卷名
无主的数据卷可能会占据很多空间,要清

【学习笔记】如何求出任意日期是星期几?
已知某年月日,如何得到这一天是星期几?已知两日期的年月日,如何得到这两日期之间相差多少天?如此种种问题,均可以利用蔡勒公式解决。
一、已知日期y年m月d日,如何求解该日期是周几?1. 问题转化该问题容易转换为计算1年1月1日与y年m月d日之间的差值。如何计算两个日期之间的差值?
不难想到,首先求解前y年的天数$w_1$,然后求解从y年1月1日到y年m月1日之间的天数$w_2$,最后求解m月1日到m月d日之间的天数(即为d天),将这三个值相加即可得到结果$w$。
得到天数$w$之后,将值与7取余,$w\mod 7 == 1$ 就是星期一, $w\mod 7 == 2$ 就是星期二,$w\mo
【学习笔记】Docker的安装
Datawhale Docker学习笔记第一篇
为了今后的方便,我选择将Docker安装在实验室的电脑上,服务器的操作系统为 Ubuntu 18.04 LTS 。整个安装过程参考这篇文章(https://vuepress.mirror.docker-practice.com/install/ubuntu)。
我曾在一款老旧的笔记本电脑上尝试过安装 Docker ,但是最终失败了,原因是 Docker 不支持 32 位的操作系统。震惊! Docker竟然不支持 32位操作系统!
由于我没有安装过老版本,因此不需要执行卸载旧版本的语句。直接执行
$ sudo apt-get update
$ s

我的2020年终总结
迟来的总结
2020年终于过去了。回首2020,我的成绩不多,教训不少;成功不多,失败不少;经验不多,教训不少;目标列得多,完成的少。
关于此博客在2020年初我给自己定下来的目标是发50篇博客。现在看来,到8月底已经62篇,算是超额完成任务。
不过自八月底开始我进入创作沉寂期,这是因为进入新学期之后,大量的重要又紧急的事情扑面而来,写博客只能无限期推迟。
但我心中还是有着写作的欲望的。通过写作,我的语言表达能力得到了极大的锻炼,很多知识也在整理博客的过程中进一步地消化和吸收。
我写博客的初衷是找一个僻静的地方,释放自己的分享欲望,同时不会打扰到我的熟人朋友们。我从来不指望自己写的内容能够被很
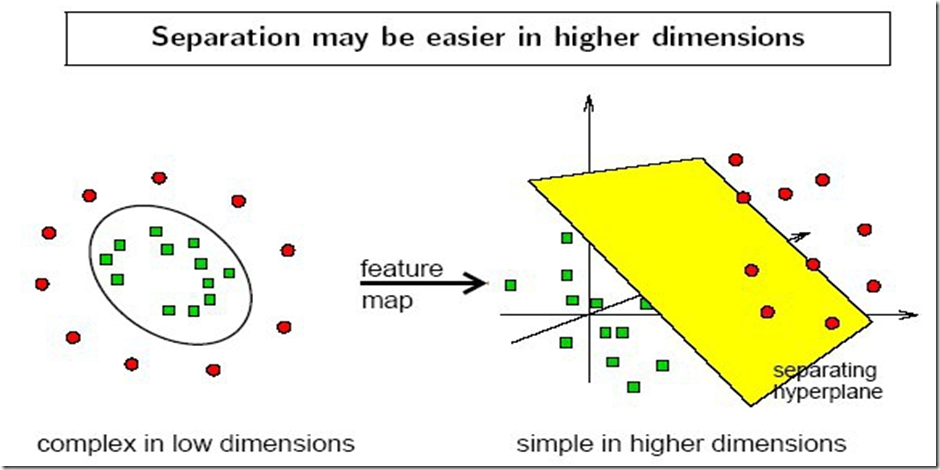
【学习笔记】机器学习——支持向量机SVM
什么是SVM?SVM是如何用于分类的?为什么求解对偶问题?核函数的原理是什么?
什么是支持向量机(Support Vector Machine, SVM)支持向量机是一种二分类模型。它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机。通过核技巧,支持向量机可以处理非线性分类问题。
支持向量机的学习算法是求解凸二次规划的最优化算法。
由于算法确定超平面时需要使用距离超平面最近的几个训练样本点,这些样本被称为“支持向量”,支持向量机由此得名。
假设训练样本
则超平面可以这样表示
这也就意味着
选取那些离超平面最近的两个不同类别的数据点,将他们带入超平面方程,发现
则两个

【学习笔记】Ubuntu 18.04 安装Go的踩坑指南
Go安装中遇到的坑
gvm是第三方开发的Go多版本管理工具,利用gvm下载和安装go。
执行以下代码时,你应该确保自己安装有curl
bash < <(curl -s -S -L https://raw.githubusercontent.com/moovweb/gvm/master/binscripts/gvm-installer)
在执行上述curl时,我的ubuntu 18.04报错
curl: (7) Failed to connect to raw.githubusercontent.com port 443: Connection refused
经过这个)帖子的指引,

【竞赛打卡】数据挖掘实践——总结与反思
这次组队学习确实是自己不太擅长的领域。借着上次NLP组队学习的冲劲,本以为想在不熟悉的领域也能至少学点东西,但确实是小看了这次学习的难度。
回头来看,组队学习进入到特征工程的时候,我已经完全一脸懵逼了。我很想跟上大家的节奏,但是确实一个是没有时间,另一个是差太多了,已经进入了恐慌区,脑海里也是拒绝的心态。我知道这次组队学习已经彻底失败了。
唉!内心充满了挫败感。这次组队学习唯一的收获就是,获得了这次比赛的Baseline。自此之后我就要投入到秋招了,我曾参加过CV赛事、NLP赛事,再加上这个结构化赛事,我的比赛经历算是圆满了,接下来的日子就是研究Baseline、好好准备简历了,也该收收心了
【竞赛打卡】数据挖掘实践——建模预测
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from tensorflow.keras.layers import Input, Conv1D, MaxPooling1D, Dense, Add, Dropout, Flatten, TimeDistributed
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import activations, optimizers, regulariz
【竞赛打卡】数据挖掘实践——特征工程
我也是加把劲骑士!
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征工程在机器学习中占有相当重要的地位。在实际应用当中,可以说特征工程是机器学习成功的关键。
那特征工程是什么?
特征工程是利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程。
特征工程又包含了 Data PreProcessing(数据预处理)、Feature Extraction(特征提取)、Feature Selection(特征选择)和 Feature construction(特征构造)等子问题,本章内容主要讨论特征构造的方法。
创造新的特征是一件十分困难的事情,需要丰
【竞赛打卡】数据挖掘实践——时间序列模型
不要停下来啊!AR模型是自回归模型,AutoRegression的简称。是一种较为朴素的时间序列数据处理方法,利用同一变量的前n期来预测本期的变量的数值,并且假定为线性关系。这种分析方法中,自变量不是其他的影响因素,而是变量本身的历史数据,利用xt-n来预测xt,因此被称为自回归。
MA模型:移动平均模型将序列{xt}表示为白噪声的线性加权。
在一个平稳的随机过程中,如果既有自回归的特性,又有移动平均过程的特性,则需要对两个模型进行混合使用,也即是较为普遍的ARMA模型,一般记为ARMA(p,q)。
ARIMA(p,d,q)是差分自回归移动平均模型,是运用最为广泛的一种时间序列分析模型。p,q
【竞赛打卡】数据挖掘实践——时间序列规则
不要停下来啊!
时间序列基本规则法提取时间序列的周期性特征进行预测,参考:时间序列规则法快速入门观察序列,当序列存在周期性时,可以用线性回归-利用时间特征做线性回归做为baseline
时间序列是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列。
时间序列分析的主要目的是根据已有的历史数据对未来进行预测。与面板数据不同,面板数据侧重于同一时间点不同样本的数值,而时间序列侧重于同一统计指标在时间的不同点的数值。时间序列有两个重要指标,一个是资料所属的时间,另一个是时间上的统计指标数值。时间序列可以描述社会经济现象在不同时间的发展状态和过程,也可以根据历史数据进行合理的未来推测。
一般地