本文最后更新于:星期四, 十一月 24日 2022, 1:19 凌晨
这是 VCED 跨模态检索介绍的第二篇,本篇将介绍 VCED 工具背后的关键框架:Jina。
Jina 是一个能够将非结构化数据例如图像,文档视频等,转换为向量数据的工具。利用该工具,可以快速实现多模态的检索任务。另外,Jina 也是一家新的公司,目前正在优化中。他们的 GitHub Repo。
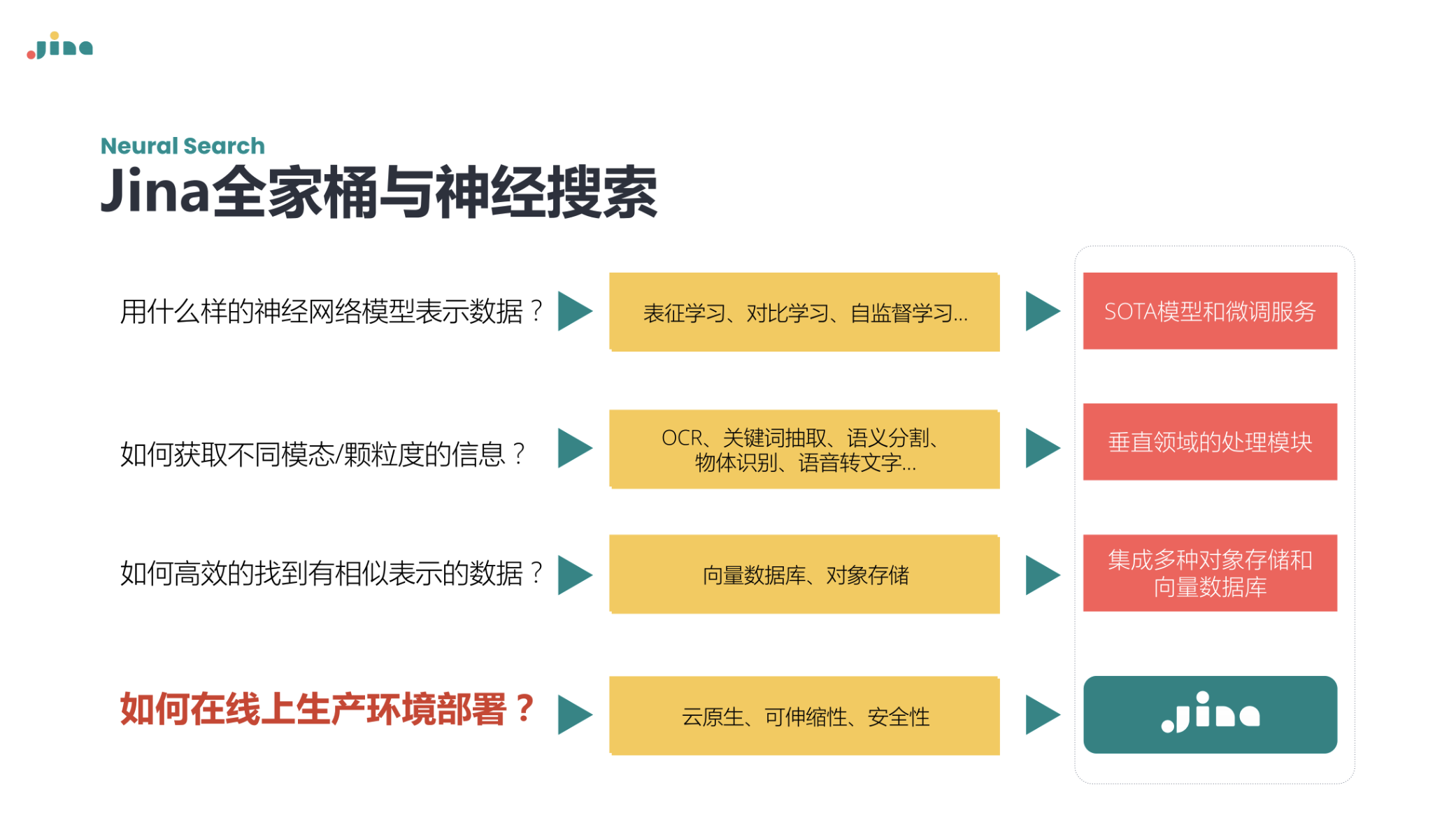
其实 Jina 公司提供了包括向量化、服务化到实际部署的全部工具,可以支持包括 PDF 检索、视频检索在内的很多检索操作。
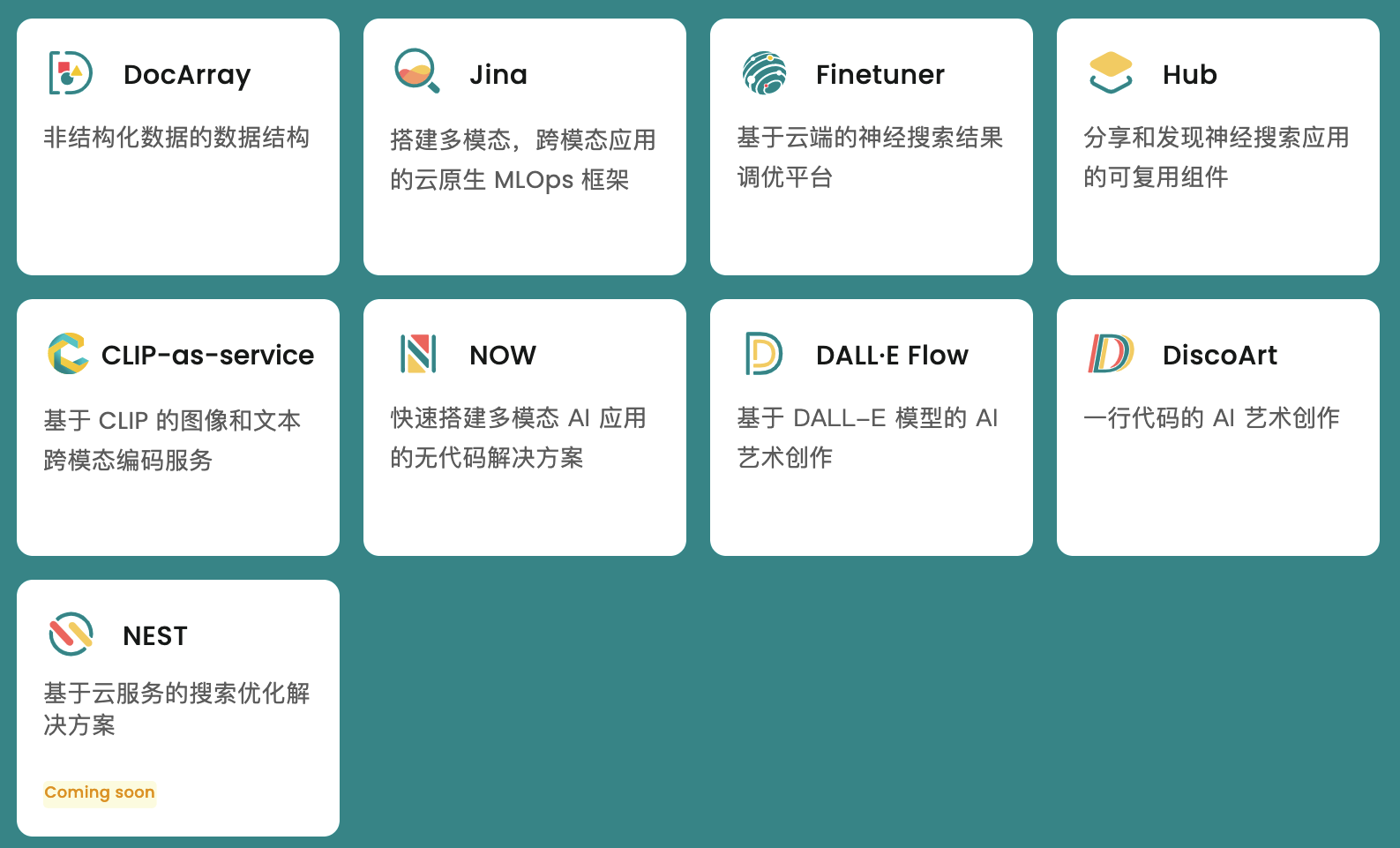
1. Jina 安装
在 windows 系统上的安装教程:
https://blog.csdn.net/Jina_AI/article/details/122820646
本文将记录在 mac 上安装 jina 的过程。
首先确保自己的 Python 版本在 3.7 及以上,然后通过下列方式安装 jina:
# via pypi
pip install jina
# via conda
conda install jina -c conda-forge
# via docker
docker pull jinaai/jina:latest
使用 pip 安装 jina 时,提示:
lz4/_version.c:32:10: fatal error: 'Python.h' file not found
ERROR: Failed building wheel for lz4
Successfully built jina docarray grpcio jcloud python-multipart
Failed to build lz4
ERROR: Could not build wheels for lz4, which is required to install pyproject.toml-based projects
原因:系统中没有 Python.h,是因为没有安装 python 的开发版,即 Python-devel 这个包。
2. Jina 的基本组件
详细的文档可以参考这里。
Document、Executor 和 Flow 是 Jina 的三个基本概念,分别代表数据类型,算法单元,和工作流。
简单来说,Document 是一种数据类型的定义方式,Flow 则是负责 Document 在整个架构间的传输,最后 Executor 则实现具体的算法功能。
比如下面这个简单的 Demo,客户端发起一个请求给服务器端,服务器端处存在定义好的 Flow,Flow 则会把不同的 Executor 串联起来。这里有两个已经定义好的 Executor,分别执行将字符串末尾添加特定字符的操作。
服务器端代码:
from jina import DocumentArray, Executor, Flow, requests
class FooExec(Executor):
@requests
async def add_text(self, docs: DocumentArray, **kwargs):
for d in docs:
d.text += 'hello, world!'
class BarExec(Executor):
@requests
async def add_text(self, docs: DocumentArray, **kwargs):
for d in docs:
d.text += 'goodbye!'
f = Flow(port=12345).add(uses=FooExec, replicas=3).add(uses=BarExec, replicas=2)
with f:
f.block()
客户端代码:
from jina import Client, DocumentArray
c = Client(port=12345)
r = c.post('/', DocumentArray.empty(2))
print(r.texts)
运行逻辑动图为:

返回结果为:
['hello, world!goodbye!', 'hello, world!goodbye!']
3. 启动 jina 示例
安装完毕后,新建 toy.yml 作为 gRPC 服务的配置文件:
# toy.yml
jtype: Flow
with:
port: 51000
protocol: grpc
executors:
- uses: FooExecutor
name: foo
py_modules:
- test.py
- uses: BarExecutor
name: bar
py_modules:
- test.py
然后定义 test.py ,定义若干 Executor 的处理逻辑:
test.py
# 创建 test.py 文件与 YAML 文件在同一目录下
# 导入 document、executor 和 flow 以及 requests 装饰器
from jina import DocumentArray, Executor, requests, Document
# 编写 FooExecutor 与 BarExecutor 类,类中定义了函数 foo 和 bar
# 该函数从网络请求接收 DocumentArray (先暂时不需要理解它是什么),并在其内容后面附加 "foo was here" 与 "bar was here"
class FooExecutor(Executor):
@requests # 用于指定路由,类似网页访问 /index 和 /login 会被路由到不同的方法上是用样的概念,关于 request 下面会再进行详细介绍
def foo(self, docs: DocumentArray, **kwargs):
docs.append(Document(text='foo was here'))
class BarExecutor(Executor):
@requests
def bar(self, docs: DocumentArray, **kwargs):
docs.append(Document(text='bar was here'))
然后使用该指令启动服务:
jina flow --uses toy.yml
启动服务之后放着别动,我们新建一个 shell 窗口;然后新建 client.py,用于储存客户端请求消息的逻辑:
client.py
# 从 Jina 中导入连接的客户端与 Document
from jina import Client, Document
c = Client(host='grpc://0.0.0.0:51000') # 如果运行提示失败,可尝试使用localhost
result = c.post('/', Document()) # 将一个空的 Document 传到服务端执行
print(result.texts)
随后启动客户端:
python client.py
最终会打印出一个 “[‘’, ‘foo was here’, ‘bar was here’]” 字符串。
4. DocArray 简介
DocArray 也是一个工具包,它被整合在 Jina 中,作为 Jina 的重要组成部分,方便实现跨模态应用。关于 DocArray 的其他资料可以参考这里。
DocArray 类比 Pandas,其基本数据类型为 Document,并整合了多种操作 Document 的方法。DocArray 对数据采用分层结构存储。
可以利用 DocArray 实现在第一层存入该画面的视频,第二层存入该视频的不同镜头,第三层可以是视频的某一帧,也可以存储台台词等等,这使得你可以通过台词去搜索到视频,也可以通过视频定位某几帧画面,这样搜索的颗粒度,结构的多样性和结果的丰富度,都比传统文本检索好很多。
5. 通过 DocArray 导入任意模态的数据
项目代码参考这里。有将图片、文本、视频分别导入 Jina 的实例。
5.1 文本数据导入
创建文本
from jina import Document # 导包
# 创建简单的文本数据
d = Document(text='hello, world.')
print(d.text) # 通过text获取文本数据
# 如果文本数据很大,或者自URI,可以先定义URI,然后将文本加载到文档中
d = Document(uri='https://www.w3.org/History/19921103-hypertext/hypertext/README.html')
d.load_uri_to_text()
print(d.text)
# 支持多语言
d = Document(text='👋 नमस्ते दुनिया! 你好世界!こんにちは世界! Привет мир!')
print(d.text)
切割文本
from jina import Document # 导包
d = Document(text='👋 नमस्ते दुनिया! 你好世界!こんにちは世界! Привет мир!')
d.chunks.extend([Document(text=c) for c in d.text.split('!')]) # 按'!'分割
d.summary()
文本匹配
from jina import Document, DocumentArray
d = Document(
uri='https://www.gutenberg.org/files/1342/1342-0.txt').load_uri_to_text() # 链接是傲慢与偏见的电子书,此处将电子书内容加载到 Document 中
da = DocumentArray(Document(text=s.strip()) for s in d.text.split('\n') if s.strip()) # 按照换行进行分割字符串
da.apply(lambda d: d.embed_feature_hashing())
q = (
Document(text='she entered the room') # 要匹配的文本
.embed_feature_hashing() # 通过 hash 方法进行特征编码
.match(da, limit=5, exclude_self=True, metric='jaccard', use_scipy=True) # 找到五个与输入的文本最相似的句子
)
print(q.matches[:, ('text', 'scores__jaccard')]) # 输出对应的文本与 jaccard 相似性分数
# 输出结果:
# [['staircase, than she entered the breakfast-room, and congratulated', 'of the room.',
# 'She entered the room with an air more than usually ungracious,',
# 'entered the breakfast-room, where Mrs. Bennet was alone, than she', 'those in the room.'],
# [{'value': 0.6}, {'value': 0.6666666666666666}, {'value': 0.6666666666666666}, {'value': 0.6666666666666666},
# {'value': 0.7142857142857143}]]
5.2 从影片导入
# 视频需要依赖 av 包
# pip install av
from jina import Document
d = Document(uri='cat.mp4')
d.load_uri_to_video_tensor()
# 相较于图像,视频是一个 4 维数组,第一维表示视频帧 id 或是视频的时间,剩下的三维则和图像一致。
print(d.tensor.shape) # (31, 1080, 1920, 3)
# 使用 append 方法将 Document 放入 chunk 中
for b in d.tensor:
d.chunks.append(Document(tensor=b))
d.chunks.plot_image_sprites('mov.png')
还有许多其他的操作方法,有待后续进一步发掘和使用。总体感觉还是很不错的。
参考
https://u84gxokzmi.feishu.cn/docx/doxcn30HXXLbqFrsyR6bL5A6o1g
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!