本文最后更新于:星期三, 十月 12日 2022, 9:44 晚上
李宏毅老师主讲的机器学习MOOC课程的笔记,本篇记录的知识点有:机器学习的概念和分类、利用线性模型解决回归问题以及梯度下降。
一、机器学习介绍
说一下我学这门课的初衷吧。其实机器学习的课程在研究生阶段就已经上过了,但是工作之后才发现有一些基础没搞懂或者已经遗忘,因此在学习新知识时存在障碍。恰逢Datawhale给了这次组队学习的机会,我便想与群友们一起把这门基础课程搞定。
1. 概要
本节通俗易懂地介绍了机器学习的概念,介绍了AI的发展历史,以及与传统规则的区别。简单来说,机器学习是一种从有限数据中学习规律并对未知数据进行预测的方法。
刚开始讲了比较多的名词和概念。老师最后的图里很好地总结了本次课的内容:
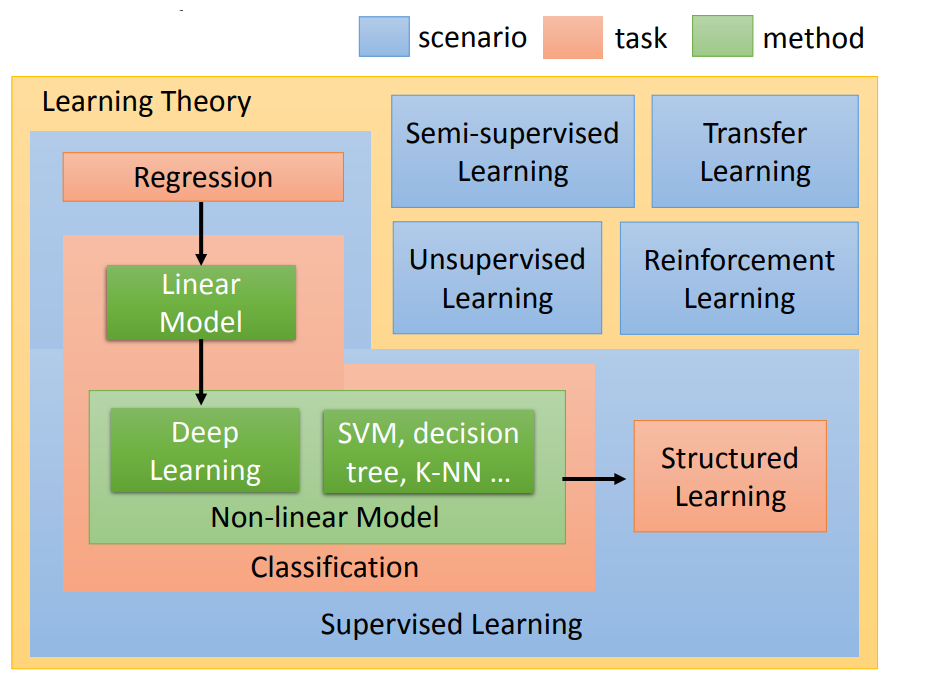
首先,机器学习的过程分成三个步骤:
- 根据问题的不同,选择模型(function);
- 根据模型的不同,定义能够度量学习效果的损失函数;
- 从有限数据中持续训练模型,使得损失函数最小。
其次,根据学习所需的数据是否存在标签,机器学习可以分成如下几类(图中蓝色框框的部分):
- 监督学习,指学习所需的数据是经过人工标注的;
- 无监督学习,指学习所需的数据不需人工标注;
- 其他学习方法,比如半监督学习、迁移学习、强化学习等。
在监督学习里,根据想要解决的问题不同,可分为如下几类(图中黄色框框的部分):
- 分类问题,指我们希望模型给出yes或no这样具体的评价;
- 回归问题,指我们希望模型能够给出一个数值,这个数值的大小有现实意义;
- 结构化问题,我们希望模型直接输出结构化结果,比如语言翻译模型能够产出一段文本,dall-e能够生成图像,等等。
分类问题是比较简单的问题,有很多模型可以解决分类问题(图中绿色框框的部分):
- 线性模型;
- 非线性模型,比如深度学习、SVM、决策树等方法。
后续我们会学到什么是线性模型、什么是非线性模型,以及上面的具体模型的设计细节。
为什么要学习机器学习这门课程?
当然是为了挣钱了
由于目前还没有一个普适的学习模型,能够解决世界一切可以用机器学习方法解决的问题,因此,我们需要依赖经验和知识,来根据不同的问题,选择不同的学习模型和和损失函数。还记得机器学习的三个步骤吗?选择模型、定义损失函数、训练模型过程的知识,都是能够帮助我们得到更加可靠的机器学习系统的技能。学习这门课程,能够帮助我们成为一名更好的机器学习工程师。
二、机器学习案例——回归问题
这部分以一个回归问题为引子,引导我们探索机器学习的三大步骤。回归问题比较普遍,像股票预测、温度预测、房价预测等,都是回归问题。
机器学习的三大步骤分别为:
- 根据问题的不同,选择模型(function);
- 根据模型的不同,定义能够度量学习效果的损失函数;
- 从有限数据中持续训练模型,使得损失函数最小。
第一步,为回归问题选择合适的模型
这里我们使用线性模型试试水。所谓线性模型 (Linear Model) 是把输入数据的各种特征,通过线性组合的方式进行预测。
其中y是预测值,x是特征本身,w是特征对应的参数。我们的学习目标就是找到正确的w,令预测值y尽可能靠谱。
第二步,为线性模型选择合适的评估函数
知错能改,善莫大焉。每当模型预测得到一个值,为了让模型认识到自己的预测值y与真实值$\hat{y}$的差距,我们不妨直接取二者之差,作为计算差距的损失函数 (Loss Function)。
这样肯定是有问题的,假设我们有两组数据,一组超过真实值0.5,另一组低于预测值0.5,它们与真实值的差值分别是0.5与-0.5。结果经过我们的计算,损失函数居然为0,也就是没有损失?
为了避免上述情况的出现,我们选择平方损失函数作为衡量差距的手段:
其实也有其他的损失函数定义方法可以规避第一个损失函数的问题,比如使用绝对值。但这里我们就钦定平方损失函数了,它有很多好处,但是我们先按下不表。
第三步,进行训练,并利用损失函数指导训练过程
到目前为止,我们有很多带标签的数据 $(x,\hat{y})$,有线性模型,有损失函数。那我该怎么得到训练好的模型呢?
最好的模型到底是什么?对于线性模型来说,其实求解最优的$w$和$b$,从而可以让我们的模型无论输入什么$x$,都能准确得到与真实值相差无几的$y$。
让我们忘掉w和b的具体含义、晦涩不清的L函数,专心解决这个问题:如何优化$w$和$b$,以便L达到最小?
一种解决问题的方法使用微积分来嗯算,通过计算导数去寻找L的极值点。运气好的话,L的变量不多,该方法看似可行;运气不好的话,我们面对的问题过于复杂、参数过多,问题就不好解决了。
还有一种笨办法是穷举所有可能的$w$,选择能使L最小的$w^*$即可。这种方法虽然可行,但是没有效率。
有一种通用的最优化方法,叫做梯度下降 (Gradient Descent) 方法,专门用于解决这种凸优化问题。使用梯度下降算法的前提是优化目标是可微的。
1. 梯度下降算法简介
恰好,我们的损失函数L是可微的,也就是二阶可导的。如果我们当初选取损失函数时,使用绝对值作为损失函数,处理起来便没有这么便利了。
梯度下降的具体过程是这样的:
- 选择一个初始$w_0$
- 计算该位置下w对L的微分,这个微分对应函数在此处下降最快的方向;
- 将$w_0$朝着这个方向移动一小步$ \eta$
- 在新的位置开始新一轮迭代计算,直到$w$不再变化为止。
不妨将梯度下降算法的求解过程想象为人下山的过程,人会先找到下山最快的方向,然后朝着那个方向走一步,直到抵达最低点。
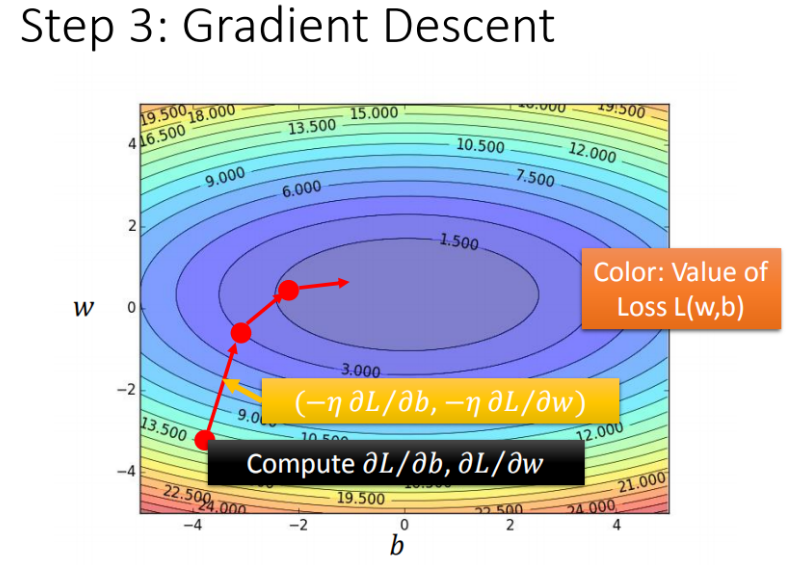
在上图中,每一条线围成的圈就是等高线,代表损失函数的值,颜色约深的区域代表的损失函数越小;红色的箭头代表等高线的法线方向。
上述过程是求解L在变量w下的最优解的梯度下降过程,但是L还与偏移量b存在对应关系,所以实际上梯度下降在线性模型的具体公式如下:
其中,偏微分的具体公式如下:
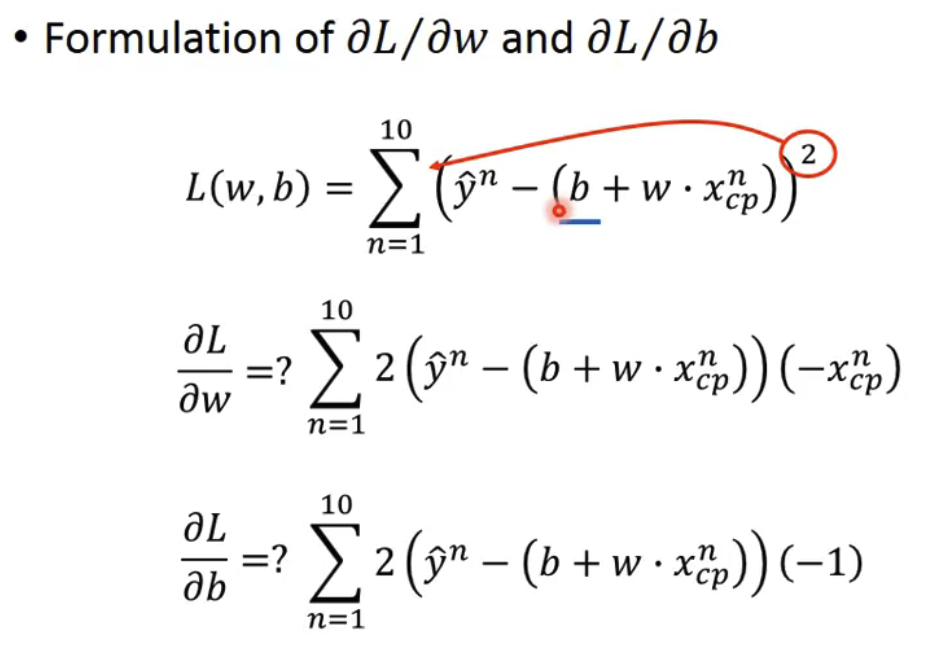
2. 梯度下降算法的局限性
首先,梯度下降算法容易陷入局部最优,找不到全局最优解。
如下图所示,当梯度下降算法优化到local minima 时,前面有座高山,它的梯度是正的,优化算法会强迫我们往回走。
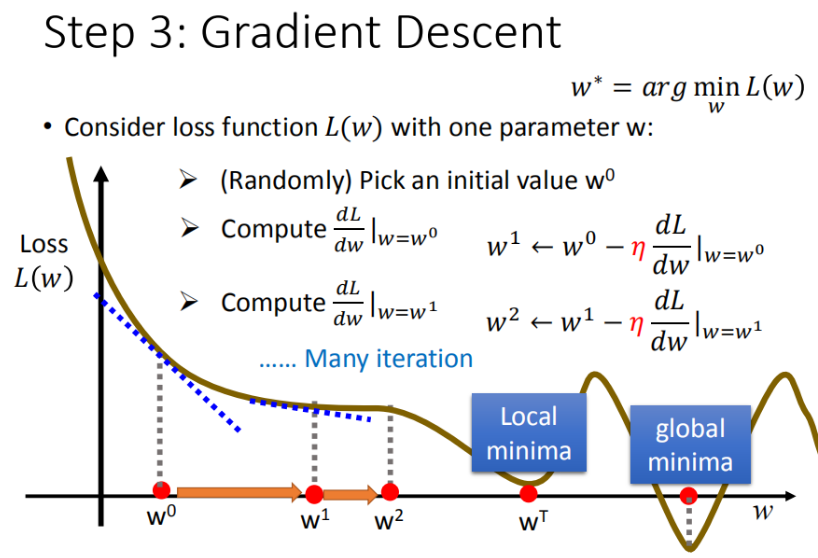
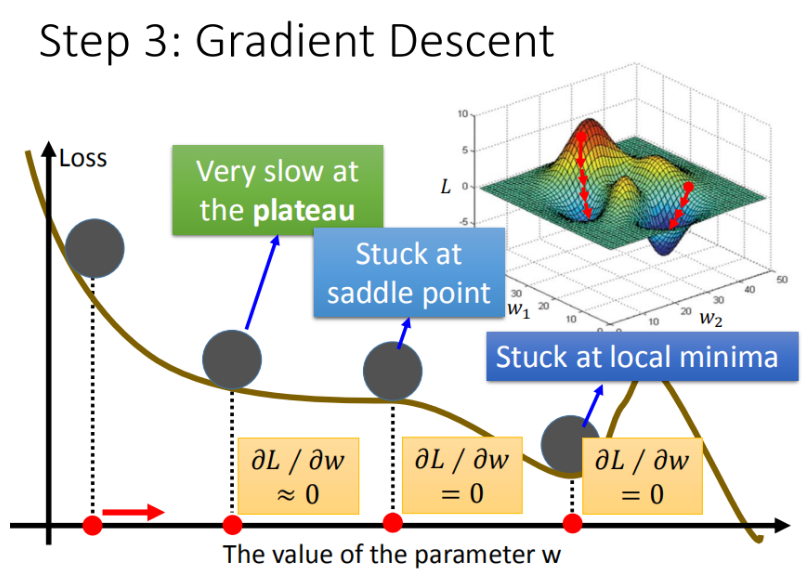
这个问题在我们的线性回归模型里暂时遇不到,因为线性模型非常简单,是一个凸函数。但当我们试图利用梯度下降算法训练复杂模型,比如神经网络时,就很有可能遭遇该问题。
有很多方法能够解决梯度下降算法的全局最优解问题,包括调整每次行进的步长$\eta$,使其更有希望跨越“大山”等手段等等。
其次,梯度下降算法要求目标函数是可微的,这在某些情况下会产生相当大的计算代价。假设我们的问题有上百万维,计算二阶偏导数就需要上万亿(百万的平方)次!
再次,当训练数据相当多时,梯度下降算法会变得很慢。在实践中,为了计算梯度$\nabla L$,我们需要为了每个训练样本x单独计算梯度$\nabla L_x$,然后求平均值。这会花费很长时间。
检验:如何检验模型是否训练成功?更加复杂的模型以及对应的风险。
经过一轮又一轮的优化,我们终于求得了该问题下线性回归模型的最优参数$w$和$b$。接下来该如何检验模型在未知数据上的泛化能力呢?
我们可以在训练之前,把数据集分成两部分,一部分用作后续的训练,另一部分用作最后的验收。如果在这部分测试数据上的表现与训练过程中的表现一致,那我们就可以验收。
这种通过划分数据集为训练集和测试集的方法,与其说是一种技术细节,不如说是一种工程实践上的经验。通过训练集和测试集的性能比较,我们可以发现模型存在的潜在问题:
1. 训练集和测试集上的表现都不太高;
这种情况我们称之为欠拟合。线性模型由于过于简单,当面对一些较复杂的现实问题时,欠拟合便出现了。你会发现无论如何训练,无论投入多少数据都很难提升模型的性能了。我们需要更加复杂的模型,然后进行上面所说的机器学习三个步骤:选择新模型,选择合适的损失函数,选择优化方法进行训练。
对于一些现实问题,类似$y=wx+b$这种一次模型确实过于简单了。比如预测房价,可能与房屋面积有关,也可以与房屋面积的平方有关,甚至是三次方、四次方。
课堂上老师举了一个例子,用一次函数模型预测宝可梦数据集,效果如下:
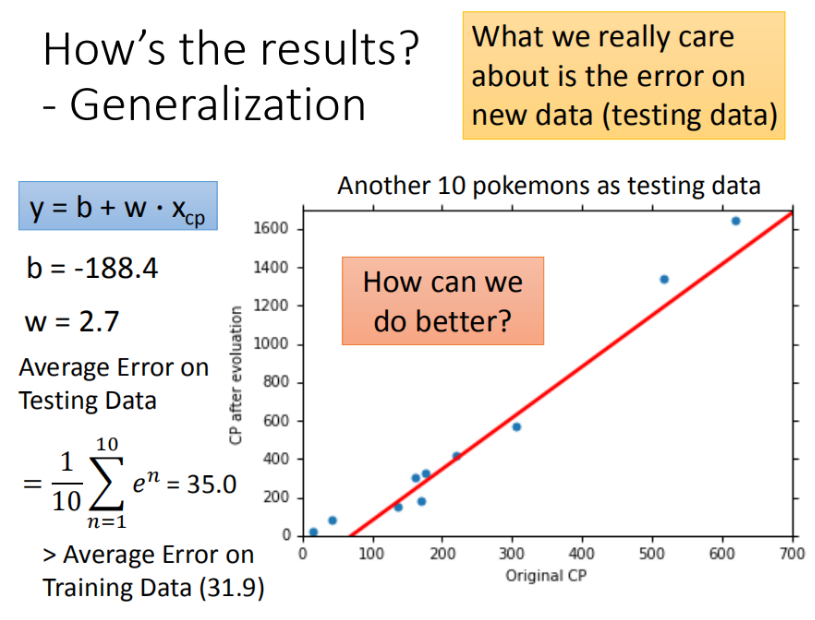
模型在测试集上的误差平均值为 35.0
当我们使用更复杂的2次模型时,模型性能有明显好转:
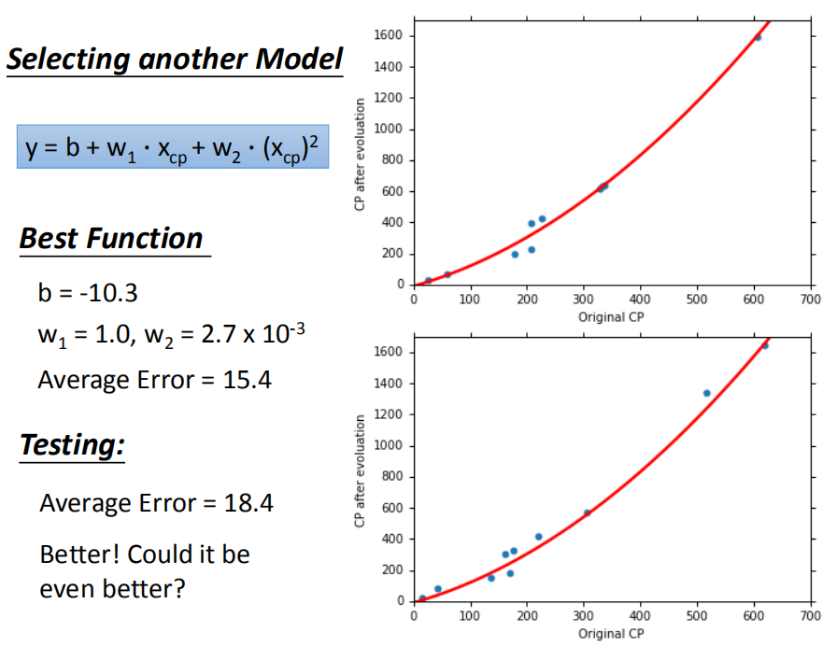
模型的图像从一次函数变为二次函数了,更好拟合了训练集和测试集。测试集平均误差降至 18.4 了。那是不是模型越复杂,性能越好呢?
2. 训练集上的表现良好,测试集上的表现很差
当我们持续优化模型复杂度到3次方函数、4次方函数时,测试集平均误差开始停滞,4次方函数的平均误差不降反增:
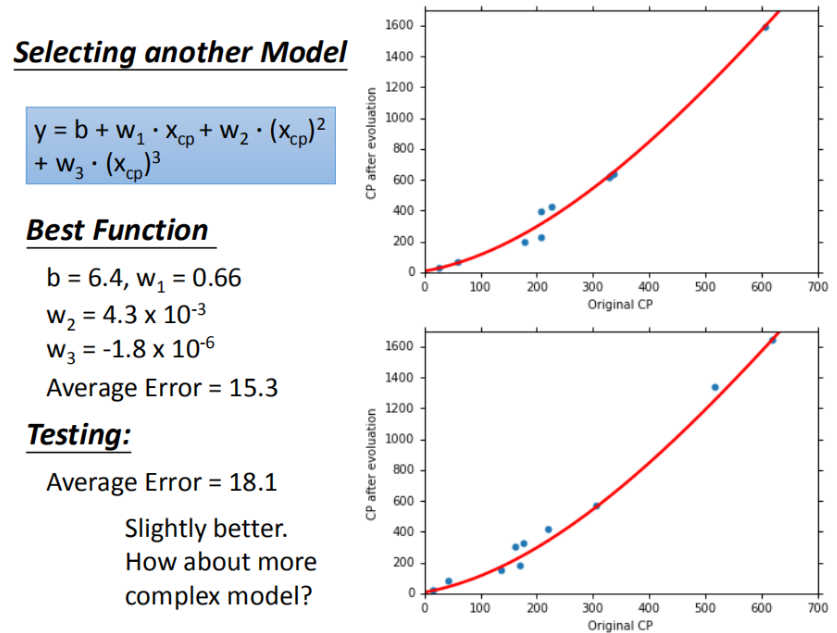
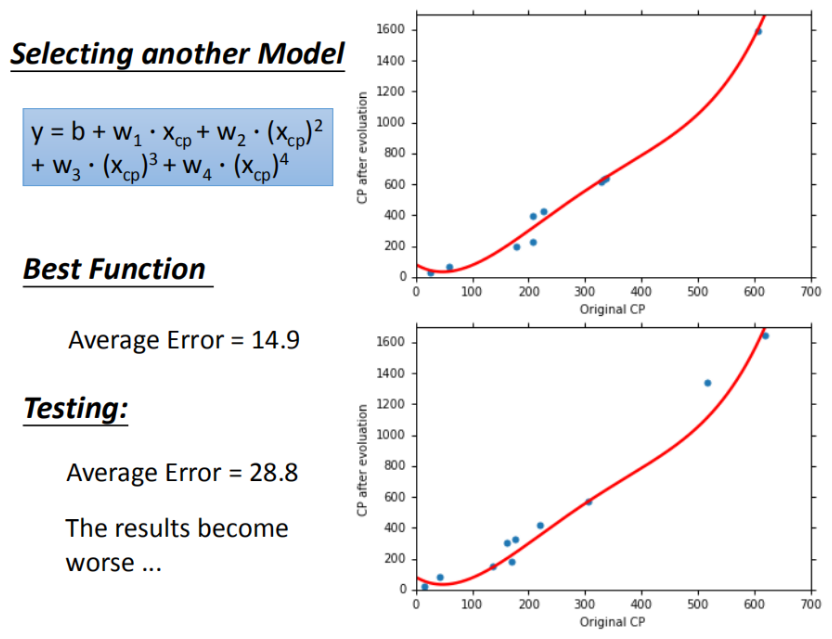
训练集平均误差【15.4】【15.3】【14.9】【12.8】
测试集平均误差【18.4】【18.1】【28.8】【232.1】
这种情况称之为过拟合。所谓“过犹不及”,那我们应该怎样选择模型的复杂度,避免过拟合呢?我们可以将模型复杂度与测试集性能之间的关系绘制成图像,通过寻找图像的“拐点”来决定模型的复杂度。

反思:改进模型性能的其他方法
上面的宝可梦CP值预测问题,老师之后给出了更多的数据,绘制在坐标图上:
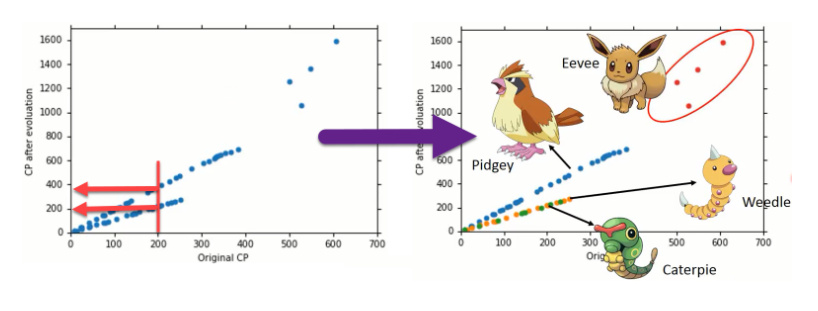
很显然,任何曲线的线性模型都没办法拟合这种数据点。这是哪里出了问题?答案是我们忽略了数据点的其他特征。当我们引入其他特征到模型后,线性模型的表达能力就增强了。下面就是引入了宝可梦种类的特征:
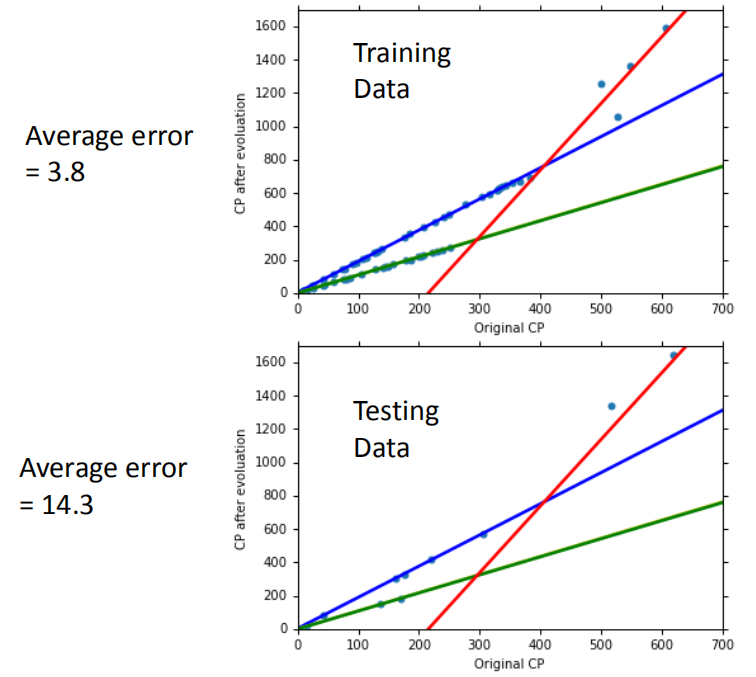
但是当我们继续引入一些无关特征,比如宝可梦的性别、年龄等,过拟合现象再次出现:
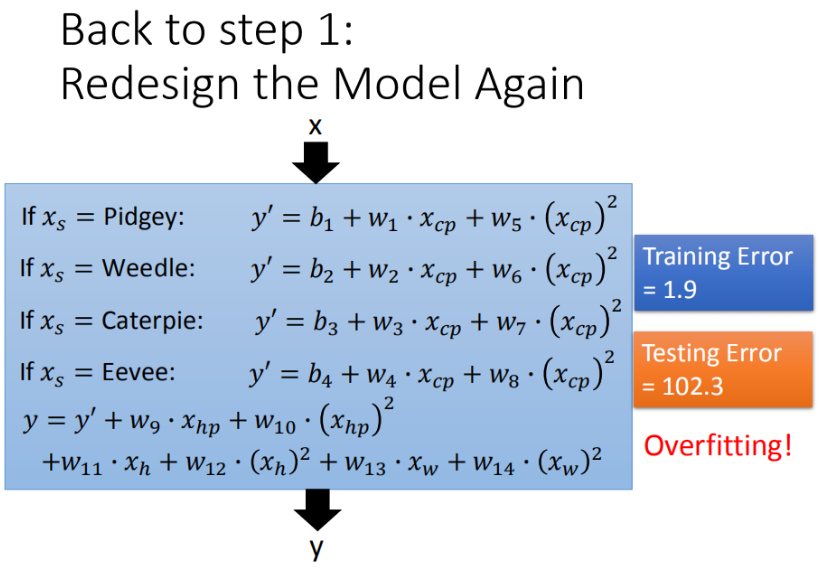
这是由于在训练过程中,某些特征的权重过大导致的。一种直观的解释是,模型训练过程也会偷懒!如果数据量不足,模型会自动选取某几个影响力大的特征,赋予较高的权值,然后忽略其他特征,那些被忽略的特征中可能包含更加有用的信息。
我们希望最终得到的模型不要出现太大的权重,为了防止某些特征的权值过大,限制权重的增长速度,可以使用正则化方法。

改造后的损失函数,末尾添加上了一个正则化项,这个正则化项的大小仅与模型的参数大小有关。参数越大,正则化项越大。有了正则化项,模型在优化过程就会更倾向于选择参数值更小的模型了。
在很多应用场景中,并不是 $w$ 越小模型越平滑越好,但是经验值告诉我们 $w$ 越小大部分情况下都是好的。
总结
- 机器学习的概念、分类和三个步骤:选择模型、选择损失函数、选择优化方法;
- 根据三个步骤,实践解决回归问题:使用线性模型,解决宝可梦CP值预测问题;
这里的重点是梯度下降算法,后面还会继续学习该算法。
- 通过分析例子的优化点,引出模型常用的优化方法以及风险:过拟合、欠拟合,以及他们的解决方案。
过拟合问题的解决方法有:降低模型复杂度、增加训练样本、增加训练样本的特征、添加正则化项等。
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!