本文最后更新于:星期二, 八月 2日 2022, 9:32 晚上
陈天奇老师主讲的机器学习编译相关的课程,回答了机器学习模型是如何从开发状态到部署状态的。整个过程类似源代码到可执行程序的编译过程,因此得名机器学习编译。据他本人所述,这门课是目前全世界第一门主讲机器学习编译的课程。
《机器学习编译》是陈天奇老师的公开课。目前在Bilibili上更新视频。这里是陈天奇老师在Bilibili的个人主页,如果对课程感兴趣的小伙伴可以免费观摩。
另外课件地址在这里:Machine Learning Compilation
一、什么是机器学习编译?学习这门课的意义是什么?
机器学习编译 (machine learning compilation, MLC) 是指,将机器学习算法从开发阶段,通过变换和优化算法,使其变成部署状态。
开发阶段:用 PyTorch、TensorFlow 或 JAX 等通用框架编写的模型描述 + 对应的权重文件。
部署状态:在考虑支撑代码、内存管理、不同语言的开发接口等因素后,成功执行在设备上的状态。
该过程类似于把源代码转换为可执行文件的程序编译过程,但是二者有比较大的不同。
首先是目标不同,机器学习编译的目标有:
- 集成打包 + 最小化依赖,即将必要的元素组合在一起以用于部署应用程序;
- 利用硬件加速,利用硬件本身的特性进行加速;
- 通用优化,以最小化内存使用或提高执行效率为目标转换模型执行方式。
这些目标没有严格的界限。
其次,这个过程不一定涉及代码生成;例如将开发状态转化为部署形式,可能只是将抽象的模型定义,转化为对某几个预定义的库函数的调用。
最后,遇到的挑战和解决方案也大不相同。随着硬件和模型种类的增长,机器学习编译难以表示单一稳定的解决方案。
那么,我们能够从这门课学习到什么?
对于在从事机器学习工作工程师,机器学习编译提供了以基础的解决问题的方法和工具。它有助于回答我们可以采用什么方法来特定模型的部署和内存效率,如何将优化模型的单个部分的经验推广到更端到端解决方案等一系列问题。
对于机器学习科学家,学习机器学习编译可以更深入地了解将模型投入生产所需的步骤。机器学习框架本身隐藏了一些技术复杂性,但是当我们尝试开始部署新模型或将模型部署到框架支持不完善的平台时,仍然会面临巨大的挑战。机器学习编译使机器学习算法科学家有机会了解背后的基本原理,并且知晓为什么我的模型的运行速度不及预期,以及如何来使部署更有效。
最后,学习 MLC 本身很有趣。借助这套现代机器学习编译工具,我们可以进入机器学习模型从高级、代码优化到裸机的各个阶段。端到端 (end to end) 地了解这里发生的事情并使用它们来解决我们的问题。
二、机器学习编译的关键要素
1. 张量和张量函数
张量 (Tensor) 是执行中最重要的元素。张量是表示神经网络模型执行的输入、输出和中间结果的多维数组。
张量函数 (Tensor functions) 指接受张量和输出张量的计算序列。
下面这张图展示了机器学习编译过程中,两种不同形式的张量函数的变换过程。从左边比较抽象的表示形式,转换为右侧较为具体的表示形式。
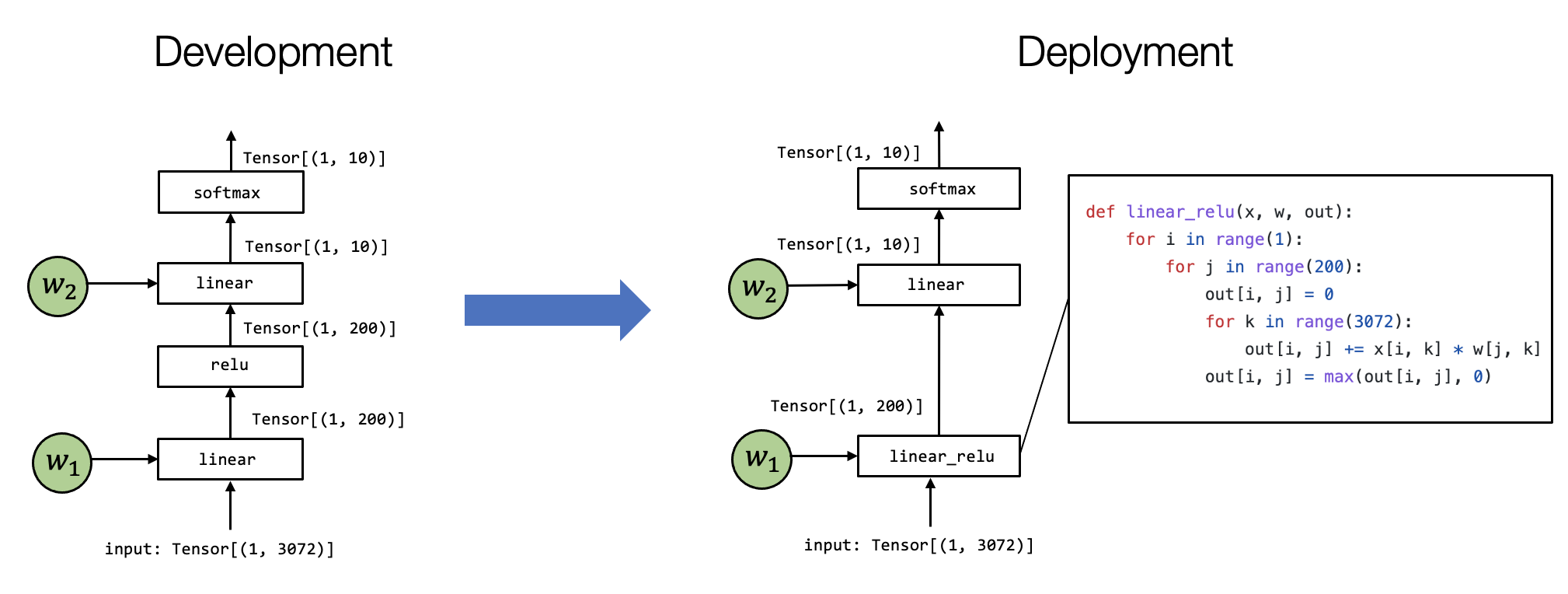
机器学习编译的过程就是是将上图左侧的内容转换为右侧的过程。在不同的场景中,这个过程可以是手动完成的,也可以使用一些自动转换工具,或两者兼而有之。
2. 抽象和实现
上一部分提到了抽象和实现。对于同样的目标,我们会有不同的 抽象表现,但是不同抽象表示有些细节不同。我们会把更细化的抽象表示称为原有抽象表示的一个具体实现。
抽象和实现可能是所有计算机系统中最重要的关键字。抽象指定“做什么”,实现提供“如何”做。没有具体的界限。根据我们的看法,for 循环本身可以被视为一种抽象,因为它可以使用 python 解释器实现或编译为本地汇编代码。
MLC 实际上是在相同或不同抽象下转换和组装张量函数的过程。
本课程会介绍四种不同形式的抽象表示
- 计算图的抽象
- 张量程序的抽象
- 算子库和运行时的抽象
- 硬件层面的抽象
notes Machine Learning Compilation
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!