本文最后更新于:星期二, 八月 2日 2022, 9:32 晚上
见多了优秀的文章,再写博客的时候就会感叹自己的学识浅薄。
本章介绍了Bert的原理和使用,具体包括pretrain和finetune两部分。
基于深度学习的文本分类
Transformer原理
当用神经网络来处理大量的输入信息时,可以借鉴人脑的注意力机制,只选择一些关键的信息输入进行处理,来提高神经网络的效率。注意力机制可以单独使用,但更多地用作神经网络中的一个组件。基于循环神经网络的序列到序列模型的一个缺点是无法并行计算,为了提高并行计算效率以及捕捉长距离的依赖关系,我们可以使用自注意力模型(Self-Attention Model)来建立一个全连接的网络结构。
Transformer模型是一个基于多头自注意力的序列到序列模型,包含编码器和解码器两部分。
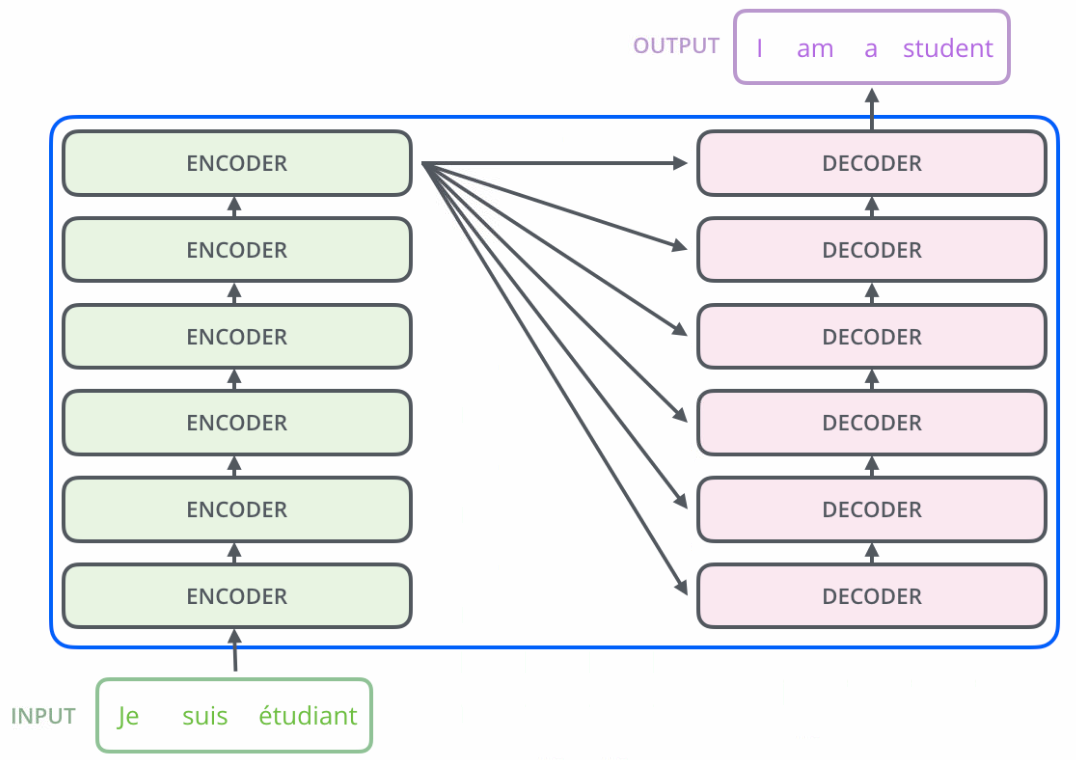
基于Bert的文本分类
分成Pretrain和Fine-Tune两部分。
notes Deep Learning Datawhale Classification attention
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!