本文最后更新于:星期二, 八月 2日 2022, 9:32 晚上
2017年的攻击文章,目标是当时防御性较高的防御性蒸馏模型,属于图像分类模型。结果是成功令其鲁棒性下降。文章最后的结论是,做防御的人应该用较先进的攻击手段测试自己的模型,同时应该注意防御对抗样本的迁移特性,即在其他弱模型上生成样本后在目标模型上测试的行为。
警告!本文为简读,大量省略了原文内容,只留下了我关注的细节。
引言
防御性模型蒸馏(Defensive distillation)是近年来抵御对抗样本攻击的最有效方法之一。防御性模型蒸馏应用于前馈神经网络,只需一次重训练,就能将攻击成功率从95%降至0.5%。
目前有两种衡量神经网络鲁棒性的方法,一是试图证明一个下界,二是攻击模型,试图展示一个上界。第一种方法显然更加难以实践,但是如果攻击算法不够好,第二种方法得到的结果也没有说服力。
本文构建一系列攻击手段,可以用于构建鲁棒性上界。
本文还建议使用高置信度(high-confidence)的对抗性示例来评估模型的鲁棒性。
对抗样本有转移性,可以使用不安全的模型找出对抗样本,这些对抗样本在采取蒸馏防御的模型上同样有效。
换句话说,有效的防御手段必须破坏转移性
总的来说,本文的贡献有以下几点:
- 引入了攻击手段,分别以$L0$,$L_2$,$L{infty}$作为距离指标。
- 调研了优化目标对生成对抗样本的影响。
背景
目前生成对抗样本的关键问题之一是添加distortion的程度。不同领域的distance metric肯定是不同的。
本文默认的攻击方法是白盒攻击,因为我们可以通过迁移的方法,将白盒生成的对抗样本迁移到目标样本的黑盒测试中。
神经网络的robustness定义为生成对抗样本的容易程度。
本文攻击的对象是以模型蒸馏为防御方法的模型。这种方法能够防御住迄今为止的大部分攻击手段。
本文攻击的模型皆为图像识别领域的m分类器,输出层为softmax层。这也就意味着输出向量维度为m,$y_i$即为样本分类为i的概率。
对抗攻击分为带目标的和不带目标的。本文将带目标攻击分成三种情况:
一般情况:在不是正确标签的标签中随机选择目标类别。
最佳情况:对所有不正确的类别进行攻击,并报告最难攻击的目标类别。
在所有评估中,我们执行所有三种类型的攻击:最佳情况,平均情况和最坏情况。
请注意,如果分类器在80%的时间中仅是准确的,则最佳案例攻击将需要在20%的案例中将其更改为0。
无论是L0,L2,Loo,没有距离度量是人类感知相似性的完美度量,并且我们没有准确判断哪个距离度量是最佳的。
防御性蒸馏:以标准方式在训练数据上训练具有相同架构的网络。当我们在训练该网络时计算softmax时,将其替换为更平滑的softmax版本(将对数除以某个常数T)。
训练结束后,输入训练集得到模型推断的标签,收集这些标签并代替真实标签,再训练第二个网络。
这样做的理由是,提出蒸馏防御的人认为,对抗样本是模型过拟合的体现,那么避免过拟合可能会消除高维空间中的盲点。
但事实上蒸馏不会增加网络健壮性。
攻击方法
L-BFGS
找对抗样本的过程建模为优化过程。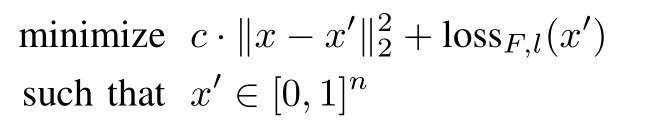
loss函数可以取交叉熵。上式求解的是c,使用的距离是$L_2$
FGSM
用的是$L_{\infty}$
JSMA
Jacobian-based Saliency Map Attack
JSMA使用的不是softmax的输出,而是softmax的输入,换句话说就是前一层的输出。$L_0$
DeepFool
$L_2$
实验设计
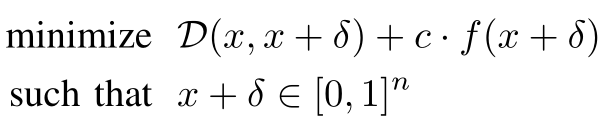
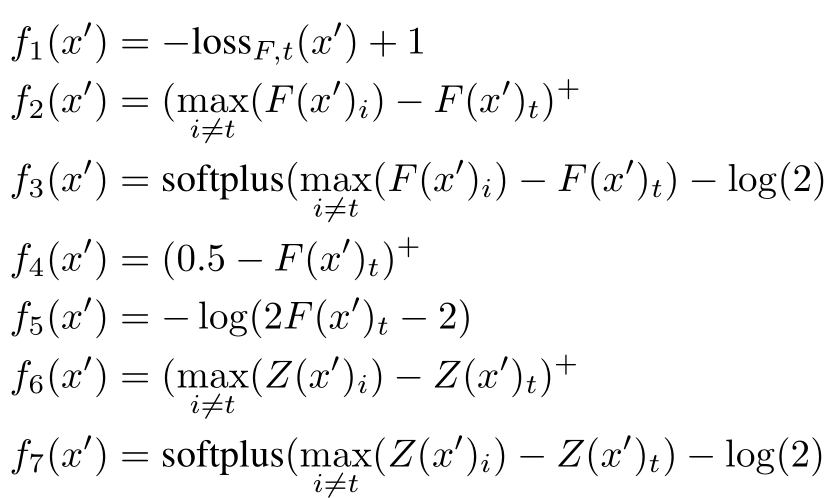
paper Robustness Deep Neural Networks
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!