本文最后更新于:星期二, 八月 2日 2022, 9:32 晚上
本文类比软件测试中覆盖率的概念,提出LSTM网络的覆盖率,并为带有LSTM网络结构的深度学习模型开发了一种覆盖率引导的模糊测试方法,并整合成测试工具testRNN。该测试主要是为了衡量网络的鲁棒性。
摘要
本文类比软件测试中覆盖率的概念,提出LSTM网络的覆盖率,为带有LSTM网络结构的深度学习模型开发了一种覆盖率引导的模糊测试方法,并整合成测试工具testRNN。
另外,本研究还发现对抗样本生成率和覆盖率有相关性,这证明覆盖率是评估带LSTM结构的神经网络的鲁棒性的良好指标,也说明了testRNN能够捕获RNN的错误。
经实验评估证明,该测试方法能有效生成使模型出错的变异样本,便于测试人员及早发现神经网络模型的问题。
本文最后解释了上面覆盖率和鲁棒性正相关的原因,认为覆盖率可提高网络的可解释性。
一、引言
回顾RNN、LSTM
这一部分可以看这里。
什么是模糊测试
这一部分可以看这里。
用覆盖率引导测试用例生成。一旦非目标随机化难以提高覆盖率,就以满足未达标测试条件的距离为目标进行突变,以生成corner测试案例。
关于覆盖率
在软件测试中,覆盖率是用来度量测试完整性的一个手段,同时也是测试技术有效性的一个度量。
在软件测试中,覆盖率是基于程序的执行情况来计算的。如果要计算语句覆盖率,覆盖率=(至少被执行一次的程序语句数)/程序中语句的总数;如果要计算判定覆盖率,判定覆盖率=(判定结果被评价的次数)/(判定结果的总数),诸如此类。
通过覆盖率数据,可以检测我们的测试是否充分,分析出测试方案的弱点在哪方面;也可以指导我们设计能够增加覆盖率的测试用例,有效提高测试质量。
但是,测试成本随覆盖率的增加而增加,因此不能一味追求构建高覆盖率的测试用例。
软件覆盖率的概念很早就有人提出来了。但是将其应用到深度学习系统中来,还是最近几年的事情。最早提出深度学习系统覆盖率的论文是这篇,可以看一下我的阅读笔记。
随后又有人定义了五花八门的覆盖率,可以看我的这篇论文、这篇论文和这篇论文的阅读笔记。
关于RNN的覆盖率,当前研究的不多,本文就算一个。
本文主要贡献
提出三个LSTM的结构覆盖率指标。
发现覆盖率越高的样本越容易令模型出错。也就是说,错误样本生成率和本文定义的覆盖率之间呈正相关。
提出的三个覆盖率指标不仅都能有效地捕捉LSTM的错误(产生令模型出错的样本),且三个覆盖率的测试目标有所不同。三者相互补充,扩展了测试的多样性。
利用testRNN工具生成的测试用例能在目标RNN模型上达到高覆盖率。
解释了测试指标背后的语义含义(semantic metrics),能帮助理解LSTM。
二、LSTM结构性覆盖率指标
LSTM结构信息
LSTM中有哪些信息值得关注?
隐状态$\boldsymbol{h}$可以代表LSTM的短期记忆,隐状态$\boldsymbol{c}$则代表相对长期的记忆。
除此之外,$\boldsymbol{f}$、$\boldsymbol{i}$、$\boldsymbol{o}$三个门的信息也值得关注。
- 遗忘门$\boldsymbol{f}{t}$控制上一个时刻的内部状态 $\boldsymbol{c}{t-1}$ 需要遗忘多少信息;
- 输入门$\boldsymbol{i}{t}$控制当前时刻的候选状态 ̃$\tilde{\boldsymbol{c}}{t}$ 有多少信息需要保存。
- 输出门 $\boldsymbol{o}{t}$ 控制当前时刻的内部状态 $\boldsymbol{c}{t}$ 有多少信息需要输出给外部状态 $\boldsymbol{h}_{t}$
$\boldsymbol{i}{t}$越大、$\boldsymbol{f}{t}$越小,代表此时的输入对长期记忆影响越大,模型整体上倾向于遗忘过去记住的长期记忆$\boldsymbol{c}{t-1}$,而代替以最新学到的短期记忆$\tilde{\boldsymbol{c}}{t}$。
如果$\boldsymbol{i}{t}$所有分量都为1,$\boldsymbol{f}{t}$都为0,则代表在该时刻$t$的输入对模型记忆影响很大,模型选择忘记长期记忆而全盘接受此时学到的短期记忆。记忆单元将历史信息清空,并将候选状态向量$\tilde{\boldsymbol{c}}_{t}$写入。
当$\boldsymbol{f}{t}=\mathbf{1}, \boldsymbol{i}{t}=\mathbf{0}$时,记忆单元将复制上一时刻的内容,不写入新的信息。
为了量化从LSTM单元的结构中抽象出来的信息值,定义结构信息表示符号:
- 定义$\mathcal{S}={f, i, o, c, h}$为五种不同的结构信息集合,代表五个可学习的网络参数;
- $s$代表$\mathcal{S}$中的任意一个,表明测试目标;
- 定义$\mathcal{A}={+,-, \mathrm{avg}}$为取正、取负和取平均三种计算方法构成的集合;
- $a$代表$\mathcal{A}$中的任意一个抽象函数;
- $t$代表时间步;
- $x$代表输入的测试用例。
根据测试目标不同、计算方法不同,构建结构信息表示符号如下:
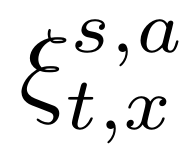
该符号表示,模型输入$x$,在$t$时间步,被测参数$s$经过$a$的计算方法取得的结果。
例子1:
$\xi{t}^{h,+}$代表$t$时间步时,隐状态$h$的分量中所有正分量的和;$\xi{t}^{h,-}$代表$t$时间步时,隐状态$h$的分量中所有负分量的和。
例子2:
$\xi_{t}^{f, \mathrm{avg}}$则代表$t$时间步时,遗忘门$f$的所有分量的平均值。
例子3:
以输入门$\boldsymbol{i}$举例来说,$\xi_{x,t}^{i, \mathrm{avg}}>0.9$就是指输入测试用例$x$到模型,在$t$时间步时,将此时$\boldsymbol{i}$向量的所有分量取平均,得到平均值大于0.9的那些时间步对应的向量。即:
含义为{$\xi$ | $t$时刻$\boldsymbol{i}$的分量平均值大小$>0.9$}
由此我们得到了三个覆盖率的定义:
Boundary Coverage (BC)
Boundary Coverage衡量结构信息$\xi^{s,a}_{x,t}$中极端情况的出现频度。
式中,$v{max}$和$v{min}$是阈值,可以取训练时产生的最大和最小值。当然这只是其中一种取法,完全可以自己选择最大阈值和最小阈值。
Step-wise Coverage (SC)
量化单步时间语义,即研究一段时间的改变。首先定义
分别计算前后时间步的正$\xi$之差与负$\xi$之差,也就是衡量短期记忆的改变程度。该值越大代表该时间步时短期记忆变化过大。由此定义SC:
式中,$v_{\mathrm{sc}}$也是可以自定义的阈值。一般情况下,选取训练过程中能达到的最大值,当做测试时的阈值。
Temporal Coverage (TC)
量化整体时间语义。首先定义所有时间步的$\xi$组成的向量集合为:
然后通过统计训练时模型的$\xi^{s, a}$值,将数据从实数域压缩成n分类数据:
在本文中用到的压缩手段是通过拟合训练集得到的分布,然后将拟合的正态分布切成三个区间。当输入测试集时,得到的$\xi$中的各个分量落到哪个区间就变成那个值。
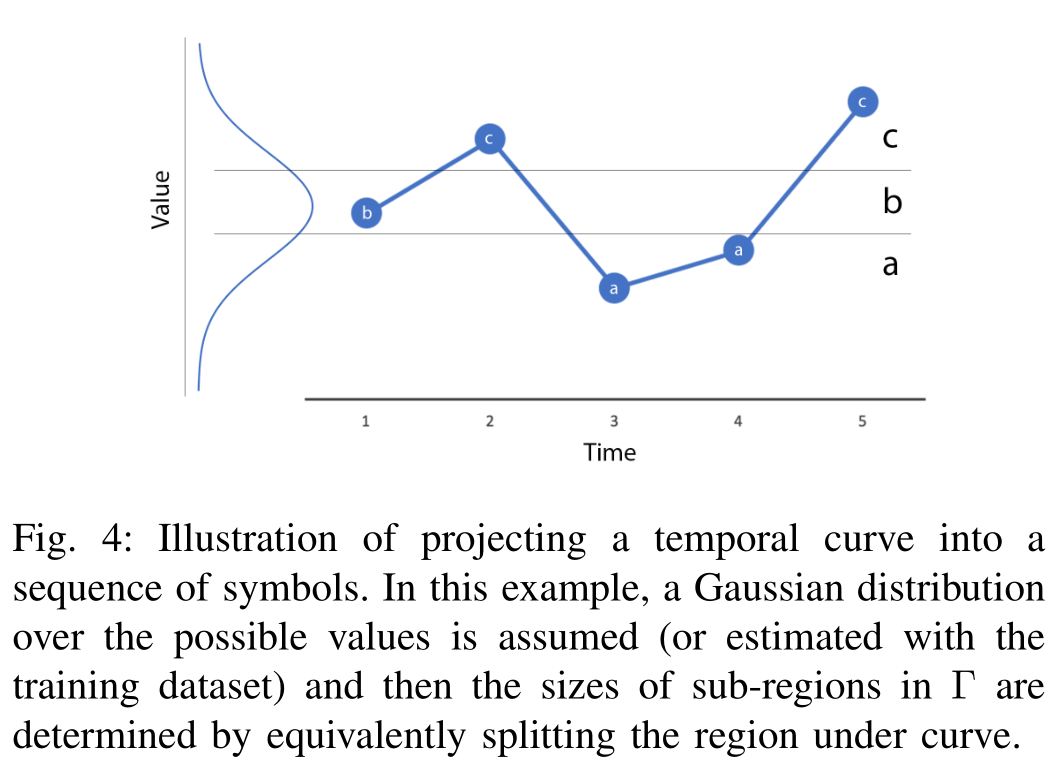
这样做的目的是简化数据计算,方便分析时间步极长的时序数据。
TC即为落到对应区间的向量占总时间步的比例。
算法
主体算法
算法整体架构:
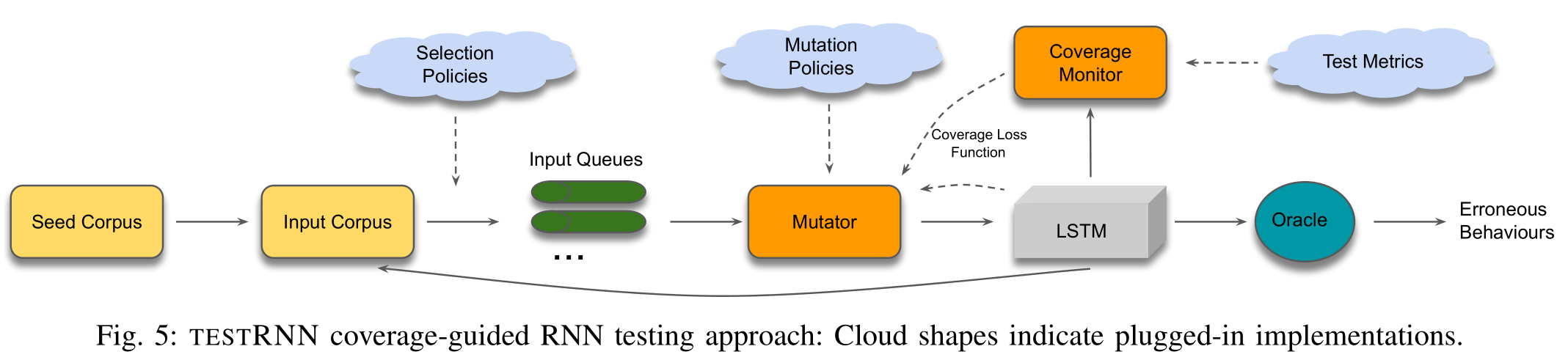
伪代码:

算法1的主体是一个迭代循环(第5-10行),只要没有达到目标覆盖水平(第4行),该循环就会继续。
在每次迭代中,从输入队列(第5行)中选择一个测试输入x,并按照预定义的变异函数m(第6行)对其进行变异。
新生成的测试输入将添加到输入语料库T(第7行)中,在此处进一步选择它们并将它们排序以进行下一次迭代。
此后,将调用Test Oracle来确定生成的测试用例是否代表网络错误(第9-10行)。
Step 1: Selection policies and queuing
所有输入样本的重要性并不相同,有些样本更容易突变产生覆盖率高的变异样本。因此要给输入样本集合排序。
testRNN优先考虑突变生成以下两种测试输入:
- 满足更多测试条件(test conditions)的样本(即,使得覆盖率上升的测试样本)
- 更可能导致模型出错的样本,比如对抗样本
本文采用的突变算法,使用的是其他的生成对抗样本的算法。
Step 2: Mutation
TESTRNN测试用例生成的核心是其Mutator引擎。
随机变异和根据RNN内部信息而特定设计的变异策略均已通过算法1中的变异函数m实现。在下文中,我们将详细讨论TESTRNN中的变异策略。
Random Mutation
对于连续输入的问题,例如MNIST手写图像识别,我们向输入中添加了具有固定均值和方差的高斯噪声,并期望变异后的输入保持其原始分类。
然而,对于离散输入的问题,例如对IMDB电影评论的情感分析,IMDB模型的输入是单词序列,其上的随机变化可能导致无法识别(且无效)的文本段落。
为了避免这种情况,我们从EDA工具包中选取了一组突变体,该突变体最初旨在增加训练数据以改进文本分类任务。 这样做的好处是,我们始终可以确保变异的文本段落有效。
在我们的实验中,我们考虑了四个突变操作,即M包括(1)同义词替换,(2)随机插入,(3)随机交换,(4)随机删除。 文本含义在所有突变中均保留。
我们定义了一组突变函数。在新迭代的开始(算法1中的5-10行),m由M中的一个函数随机实例化。
Targeted Mutation
当随机突变难以提高覆盖率时,我们可以使用目标突变,仅当新测试用例在某些预定义的覆盖损失函数上优于现有测试用例时,才选择新的测试用例。
对于关于某些$s\in\mathcal{S}$和$a\in\mathcal{A}$的三类测试条件(BC,SC,TC),我们将覆盖损失函数定义为到它们各自目标的距离,例如
,其中$t$,$t1$,$t_2$为 可以从上下文中推断出的时间步长,$u{x}^{[t1,t2]}$表示输入为$x$时,在时间段[t1,t2]内所有$\xi^{s,a}$的符号表示,而$u_{\text{target}}$是目标符号表示。 $\left|u_1−u_2\right|_0$是汉明距离,计算两个符号表示形式$u_1$和$u_2$之间不同元素的数量。
直觉上,覆盖损失$J(x)$用来估计达到未满足测试条件的距离。

通过生成旨在逐步减少损失的测试用例,目标突变是一种贪婪的搜索算法。
Step 3: Test Oracle
oracle的中文术语为“结果参照物”,在软件测试中也就是程序预期输出。
通常使用测试预言 (Test Oracle) 来确定测试用例是否通过。给定一个系统的输入,如何区分相应的期望的、正确的行为和潜在的不正确行为,被称为 “Test Oracle Problem”(测试预言问题)。之所以测试预言在软件测试中是一个问题,主要还是其难以自动化,导致软件测试人员采用肉眼人工测试,效率极低。
对于testRNN,测试预言包含两个条件:
(1) 与x’原测试用例x相差小于指定距离,即$\left|x-x’\right|p\leq\alpha{oracle}$;
(2) 模型给出的分类与原阿来不同,即$\phi(x)\neq\phi(x’)$;
我们就把$x’$这种没能通过测试预言的测试用例,成为对抗样本。
条件(1)使用一个限定条件(constraint)来确定生成的测试用例不会被人类察觉,条件(2)则确保生成的测试用例能够令模型出错。
!!注意,这里其实默认了一件事,那就是对深度学习模型的测试过程,就是找对抗样本的过程。但我个人对这种目的存疑。
给定一个LSTM网络和一个特定的测试指标,一旦生成了测试用例,那么攻击率就是未通过预言的测试用例的百分比。
adversary rate:
生成测试样例中对抗样本所占比例。
coverage rate:
生成测试样例中满足覆盖率要求的样例所占比例。
三、评估 Evaluate: Research Questions
RQ1. 为什么我们需要新的覆盖率指标:NC不行
RQ2. 覆盖率和对抗样本的关系
RQ3. 覆盖率能够发现不同的RNN错误吗?
RQ4. 测试用例生成算法能达到高覆盖率吗
RQ5. 变异半径和对抗样本生成率的关系
RQ6. 这些测试指标和测试结果能帮助解释LSTM内部决策逻辑吗?
实验设置
待测模型
作者训练了四种不同的模型,分别对应手写数字识别任务、情感分类任务、化学分子式亲油性预测任务、人体姿势识别任务。不同任务下,模型有些许不同,但都使用了LSTM层。
测试指标
- BC ($\xi^{f, avg}_{t}$)
- SC ($\Delta\xi^{h}_{t}$)
- TC+ ($\xi^{h,+}_{t}$)
- TC- ($\xi^{h,-}_{t}$)
变异方法
- 手写数字识别任务,在输入图像中随机加入高斯噪声。
- 情感分类任务,使用EDA工具包对文本进行变异。
- 化学分子式亲油性预测任务,采用Python化学信息学包RDkit对化学式进行变异。
- 人体姿势识别任务,在原始视频帧中添加高斯噪声。
变异距离限制
为了防止生成的测试用例彻底改变语义,或者是为了降低变动被人类察觉的可能性,我们必须对变异本身加以限制。
$\alpha_{oracle}$越大,对变异的限制越宽,生成的测试用例与原测试用例差别也就越大。
- 手写数字识别任务,欧氏距离限制$\alpha_{oracle} = 0.005$
- 情感分类任务,$\alpha_{oracle} = 0.05$
- 化学分子式亲油性预测任务,$\alpha_{oracle} = \infty$,对变异不加限制,能否通过Oracle完全取决于分类结果。
- 人体姿势识别任务,$\alpha_{oracle} = 0.1$
RQ1. 为什么我们需要新的覆盖率指标
答:因为传统的NC不行。
首先要介绍一下NC是什么。
NC是DeepXplore论文中提出的一种朴素地计算神经网络覆盖率的方法,适用于前馈神经网络的全连接层。
输入测试用例x,某一层神经网络的神经元覆盖率为:
如果输入一批测试用例,此时只要激活过一次的神经元都算作Activated Neurons。因此随着测试用例变多,NC覆盖率会先升高、后趋近于100%。
在循环神经网络中如何计算覆盖率?如果我们将一个LSTM网络结构抽象为一层,那么该层的输出向量就是最后的隐变量$h$。
覆盖率的计算方法如下:
下面分别是三种不同任务下,随着输入测试用例变多,覆盖率的变化曲线。
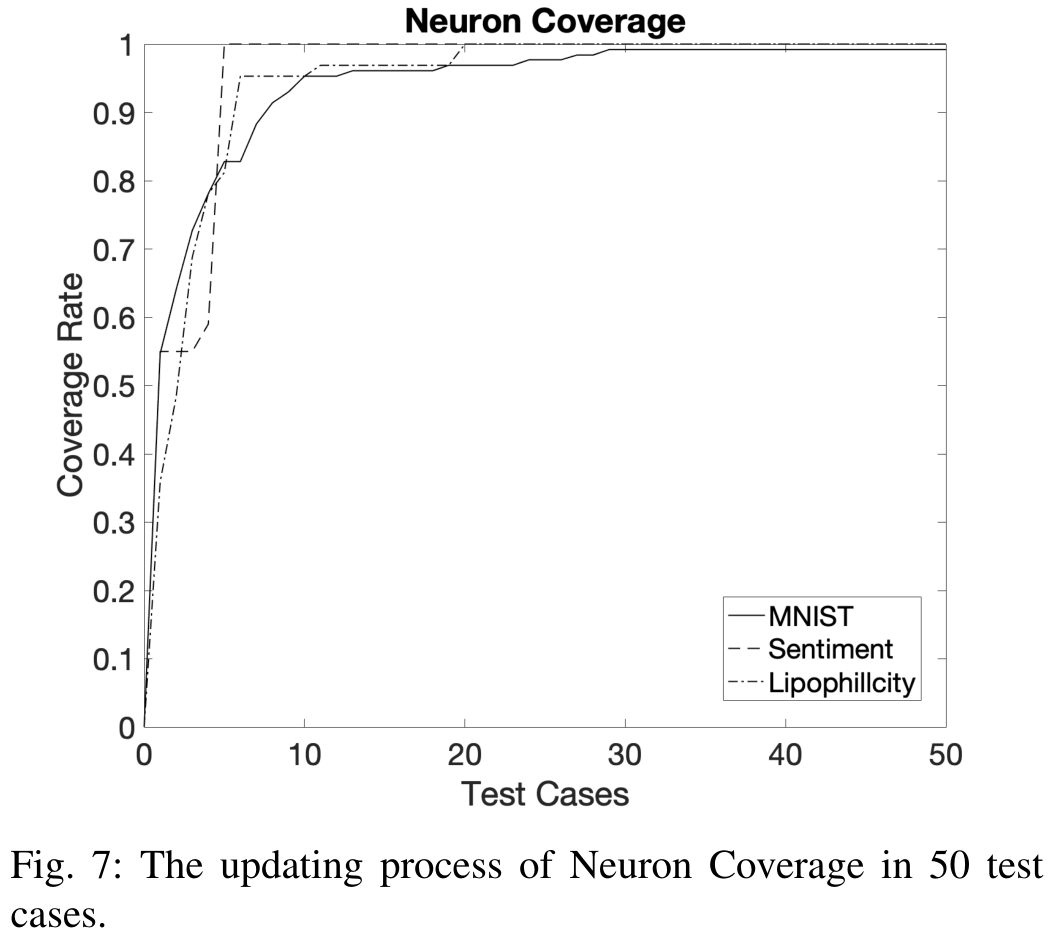
可以看到覆盖率曲线不论在哪个任务,都很快就上升到100%。这种覆盖率没有区分度,也就是说,测试用例好与坏无法凭借覆盖率区分开。所以这种覆盖率无法满足我们引导测试用例生成的需要。
RQ2. 覆盖率和对抗样本的关系
此处我又有疑问,生成了对抗样本就一定代表模型有缺陷吗?生成对抗样本的难度与模型的好坏有什么关系?这篇论文并没有回答这个问题,而是默认了“对抗样本生成就代表模型的错误”,并根据这个命题走下去了。
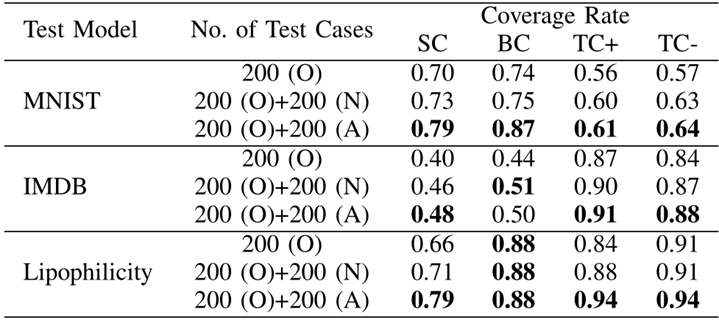
上表中,分别以三个模型的测试任务,说明了对抗样本的确能够使得覆盖率上升。
- 200(O)代表Original,未加扰动的原始样本
- 200(N)代表Normal,加了扰动,但是没有改变标签的良性变异样本
- 200(A)代表Adversarial,加了扰动并且令模型错误的对抗样本
SC/BC/TC+/TC-分别是之前定义的四种不同的覆盖率。
在表格中,良性变异样本的覆盖率比未加扰动的覆盖率高,对抗样本的覆盖率比良性变异样本的覆盖率又高。因此可以说明,对抗样本的确能使得覆盖率上升。
其实相关性也不是特别显著。。。
RQ3. 覆盖率能够发现不同的RNN错误吗?
这个问题是想问,不同的覆盖率的测试目标是否有差别?毕竟如果只是针对同一目标进行测试,那么不同的覆盖率只是数学游戏罢了。
设计实验,分别以SC/BC/TC+/TC-为指标,力图在保证高覆盖率的同时,最小化测试用例数目。
那么如果以SC为目标最小化的测试用例集合,不能使得其他覆盖率升高,就能在某种程度上说明,SC的测试目标与其他三种覆盖率有所不同。
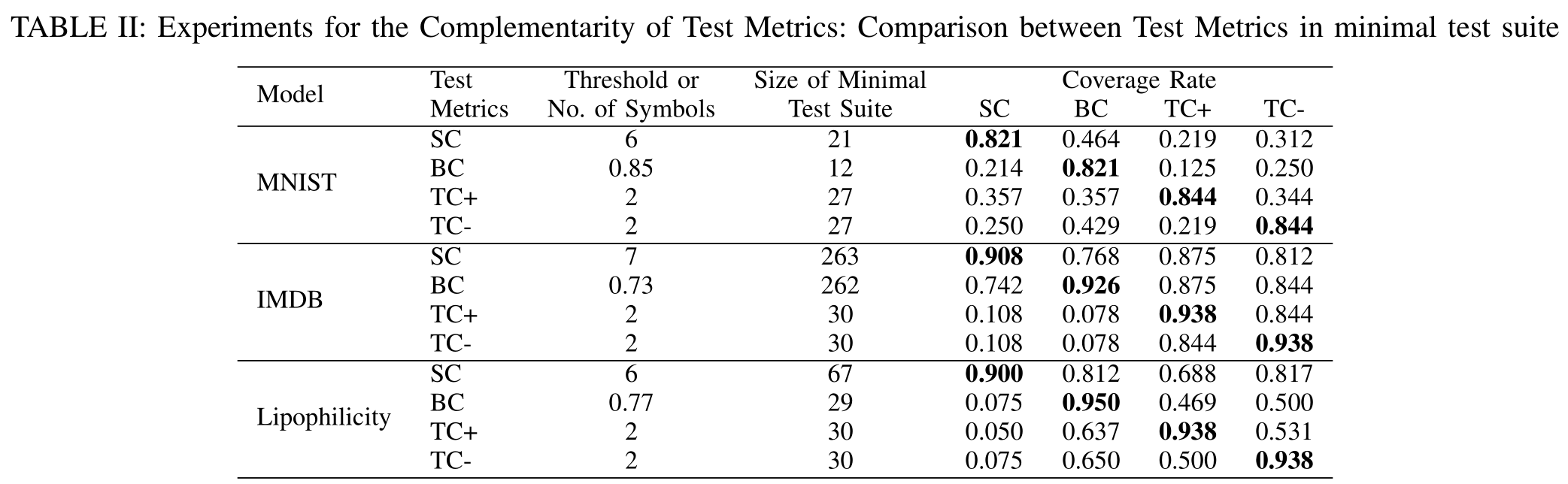
这个实验设计还是比较精妙的,值得借鉴其思路
从表中我们可以看出,以各自覆盖率为优化目标的最小测试集合,都不能使得其他覆盖率得到很大提升。从而可以从侧面佐证作者的想法。
实际上,BC考虑的是抽象信息的值,SC考虑的是值的单步变化,TC考虑的是值的多步变化。
它们的设计涵盖了RNN的时间语义的不同方面。
RQ4. 测试用例生成算法能达到高覆盖率的同时生成对抗样本吗
这个问题是想问该方法的有效性。从以下几个方面证明测试案例生成的有效性:(1) 实现高覆盖率并非易事(证明其他方法的无效性); (2) 在生成的测试用例中有相当数量的对抗样本。
随机突变不能提升测试用例的覆盖率,需要有针对性的突变(即通过覆盖知识增强的随机突变)来提高覆盖率
考虑了三种测试用例生成方法:
- (SI)对来自训练数据集的500个种子输入进行采样;
- (RM)通过使用随机突变 (random mutation) 从500个种子中生成2000个测试案例;
- (TM)通过使用针对性突变 (target mutation) 从500个种子中生成2000个测试案例。
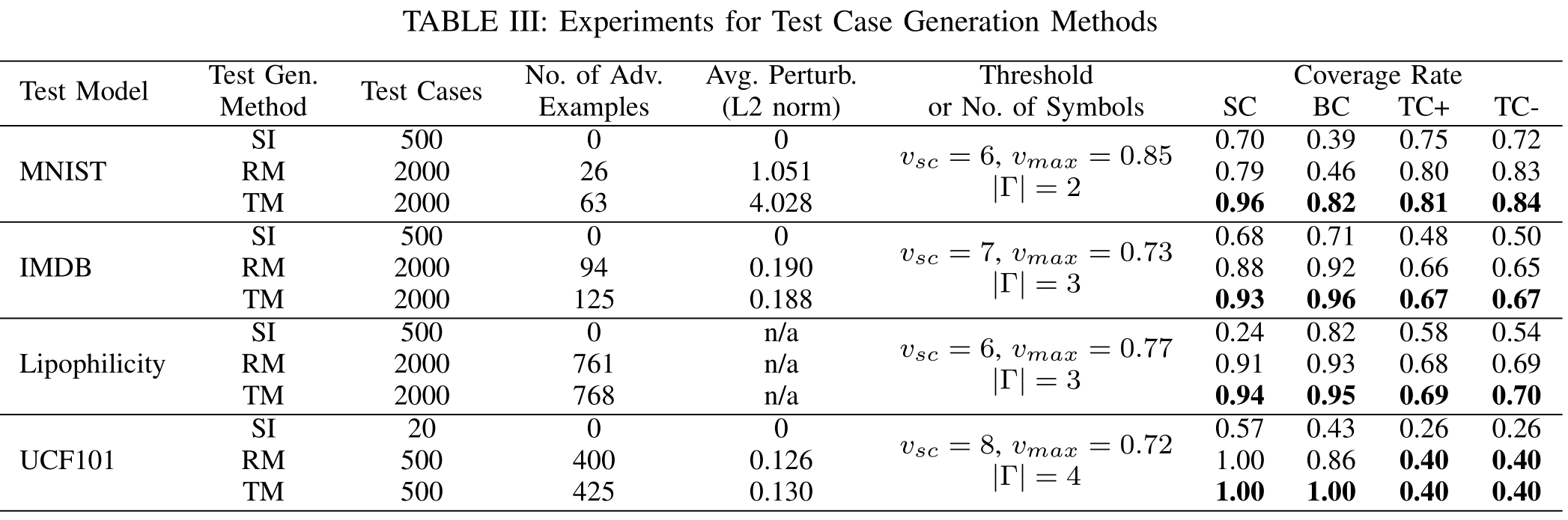
表格中表明只有target mutation得到的测试用例,才能够使得覆盖率达到最高值。
另外从表格可以看到,target mutation比其他方法更高效地生成了对抗样本。
RQ5. 变异半径和对抗样本生成率的关系
如果将每个测试用例当作某个高维空间中的一个点,那么以原测试用例为圆心、以变异距离$\alpha_{oracle}$为半径画一个球,这个球的内部就是我们能忍受的变异样本的生成区域。
直观上,对抗样本生成率随变异半径单调增加。实验结果也证明这一点。
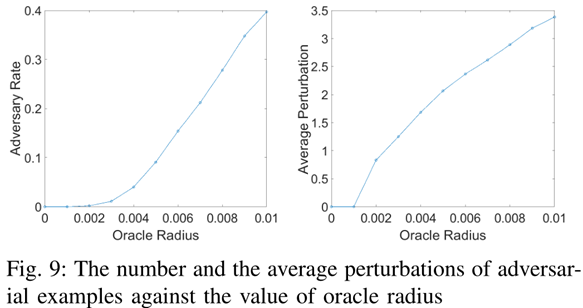
根据变异距离与对抗样本生成率的变化曲线,我们可以得到有用的结论:
曲线的斜率、面积等可用于衡量模型鲁棒性。陡峭曲线说明鲁棒性差,大面积说明鲁棒性差。
RQ6. 这些测试指标和测试结果能帮助解释LSTM内部决策逻辑吗?
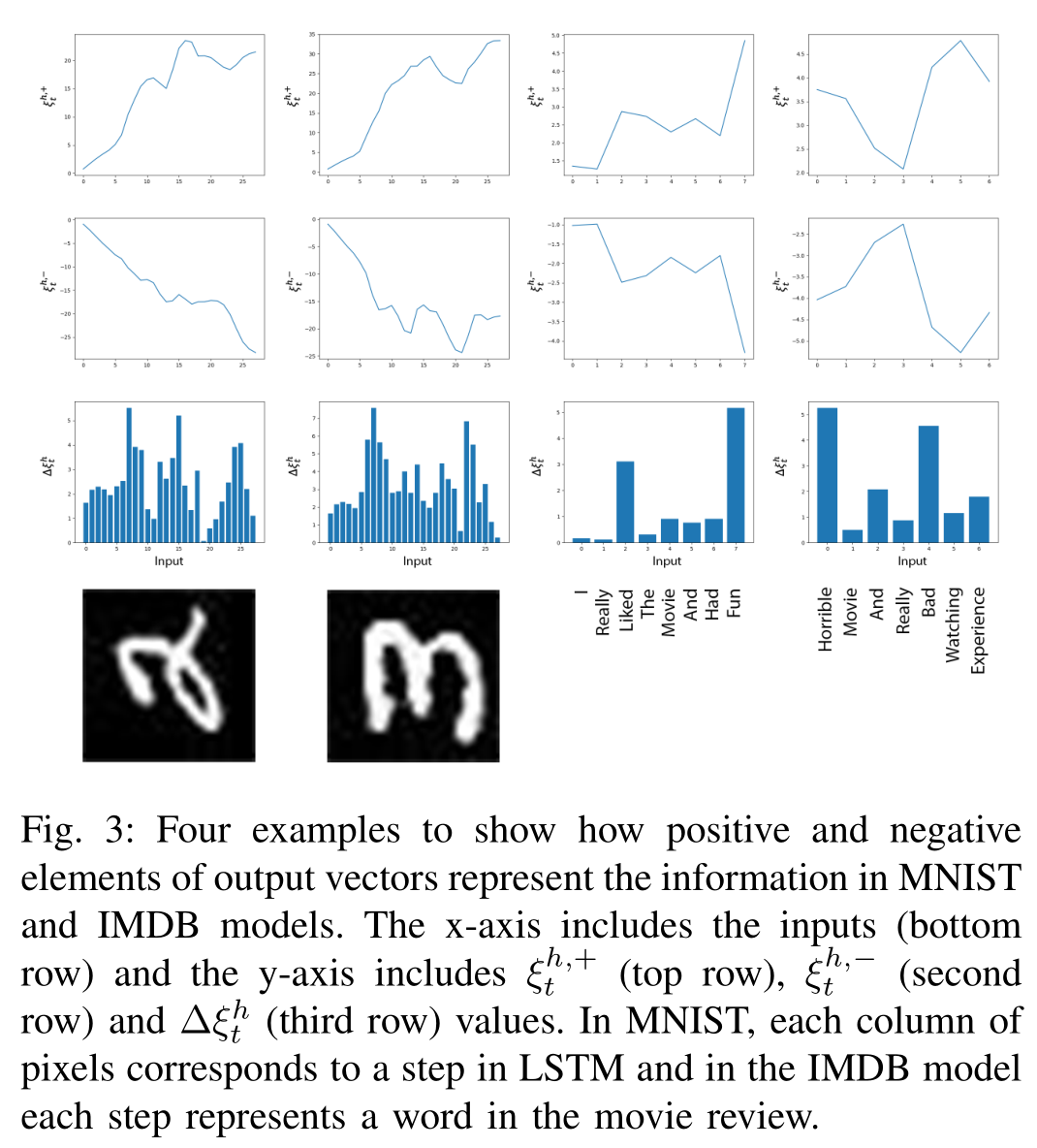
MNIST手写数字识别模型的覆盖率分析
下图是MNIST手写数字识别任务利用LSTM模型实现,横坐标是28个Input Feature(其实是每张照片对应28行像素向量),LSTM层将每个Input Feature依次读入,比如时间步t=1的时候读入第一行,t=2读入第二行,以此类推。
纵坐标则是覆盖次数。Step-wise Coverage的计算方法还记得吗?
当我们输入一张图片,这28个Input Feature就会分成28个时间步,每个时间步都会计算是否满足SC。当我们继续输入整个测试集,每个时间步的满足次数累加起来,就是纵坐标。
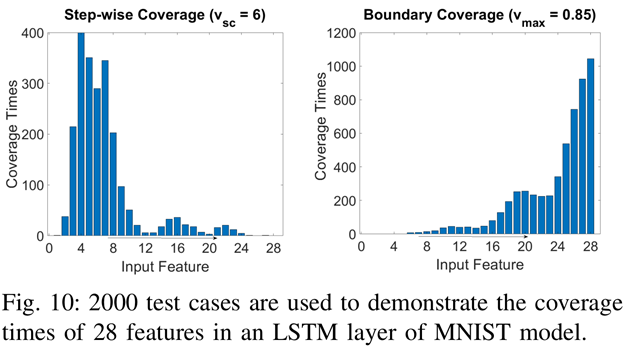
同理,Boundary Coverage也是如此计算Coverage Times。
我们可以分析左图SC的变化:
- 开始和结尾的Feature代表图像边缘,SC覆盖率低代表模型不学习;
- 第4和第7个Feature往往容易出现敏感像素;
- 模型在最后几个时间步拒绝学习新知识(只用老知识就判断这张图是什么数字)。
右图是BC的变化($v_{\max}$故意选择比较高的0.85):
- 开始时学新的、忘旧的;
- 长期记忆$c_t$往往在时间序列结束时懒散地更新
这也与BC反应长期记忆、SC反应短期记忆相吻合。
IMDb情感分析模型的覆盖率分析
下图是IMDb情感分析模型的覆盖率图:
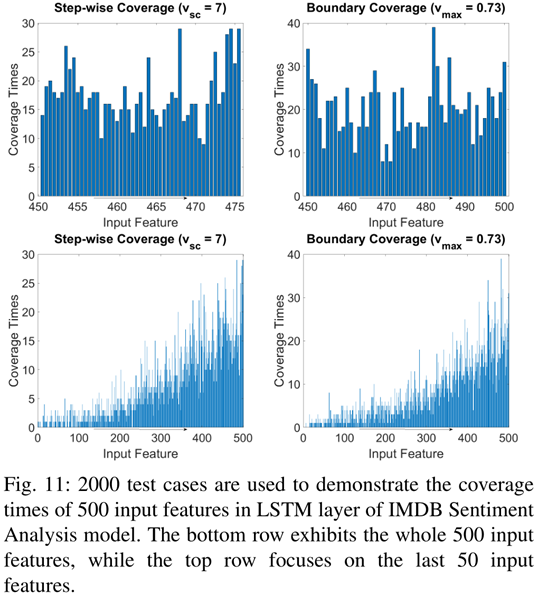
IMDb情感分析模型的输入是长度为500的整型数组,每个整数代表一个单词每个单词为一个feature,上面两个是最后50个feature的图,底下两张图是所有500个feature的图。
关于IMDb影评情感分类任务的LSTM模型解决方案,可以参考我的这篇博客文章。
比较MNIST任务可知,IMDb任务模型不像MNIST任务模型那样有固定的工作模式,文本中的敏感词可能会出现在文本的任何地方
四、总结
这篇文献阅读报告我鸽了好久,从3月25号决定写,到现在6月22号初步写完。其实这篇论文我在去年的时候就已经打印出来,粗略地读过一遍;去年年底要开题的时候又仔细地读了一遍,但是那次并没有像这次一样,读懂内部的所有细节。
通过这次编写文献阅读报告的过程,我能感觉到自己对这篇论文的理解更深入了,一个重要的标志就是我能够体会这篇论文内部的缺陷和漏洞,以及确定了值得深挖的方向。
显然不可能每篇论文都如此阅读,鉴于这篇论文对我的工作有指导意义,所以之前的工作不会白费。
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!