本文最后更新于:星期五, 十一月 18日 2022, 8:04 晚上
C++的字符串操作非常多,功能也非常多样化,熟练使用标准库提供的字符串操作函数能够高效提升我们编写代码的效率和可读性。除了常用的
一、常见的基本操作回顾
必须指明,
部分函数,包括insert和erase等函数可分为两类,如果输入的位置参数pos为整数int,此时返回值为被插入字符串的引用;而输入的位置参数类型为迭代器iterator,则会调用返回迭代器的函数,该迭代器指向被插入部分的头部。
而且
这些同名、功能相似但不同参数的函数使得C++新人学习标准库时容易产生极大的困扰。
1. 构造string
const char * cp = "Hello World!!!";
char noNull[] = {'H', 'i'};
输入一个char类型的指针,以及偏移量。转换从指针开始的偏移量个字符。
如果未指定偏移量,则默认转化到碰到’\0’为止。
没有’\0’结尾则该行为未定义。
string s1(cp); // 从C风格字符串转化
string s2(noNull, 2); // 指定转化的字符个数
string s3(noNull); // 未定义,因为noNull不是以空字符结尾
string s4(cp + 6, 5);
拷贝构造函数,从其他string拷贝
指定拷贝位置和拷贝字符个数
不指定pos则默认从头拷贝
不指定len则默认从pos开始全拷贝
pos越界则抛出异常
len越界没问题,只到’\0’
string s5(s1, 6, 5);
string s6(s1, 6);
string s7(s1, 6, 20);
string s8(s1, 16);
substr函数,输入pos和len
返回由该字符串的第pos位置拷贝len个字符组成的新子串
string s9 = s1.substr(0, 5);
2. 改变string
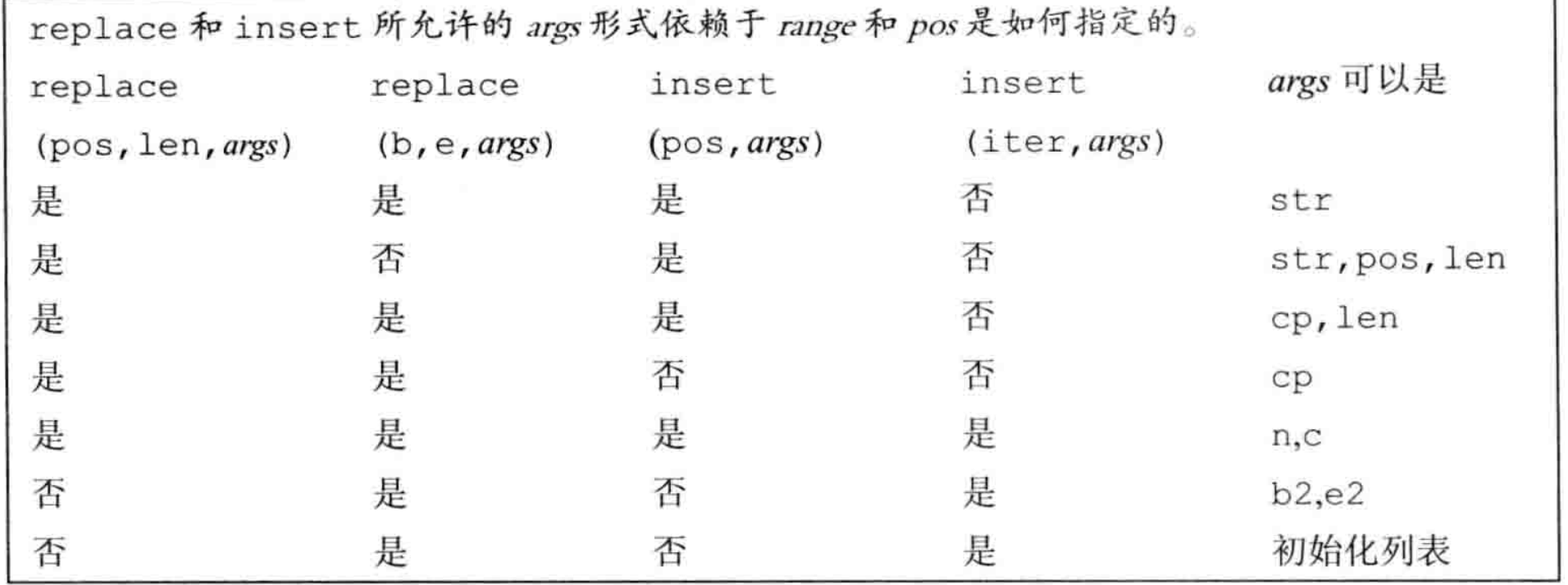
以insert为例,简单介绍不同参数重载的不同insert。
insert除了接受迭代器的版本之外,还有直接接受下标的版本。返回值为被插入字符串的引用。
s.insert(pos, count, char)
s.insert(pos, char_ptr, len)
s.insert(pos, string, pos, len)
第一个位置总会是pos,表示被插入位置;
第二个参数如果是个数,那么你调用的是第一个insert函数,其含义为重复插入第三个参数char所制定的内容;
第二个参数如果是C风格字符串,那么第三个参数可以指出插入长度,不指名就默认把该C风格字符串全插到pos的位置;
第二个参数如果是string,那么你还需在string参数后指定从哪个pos开始插,并且指定len表示插入多少个。相对于插入C风格字符串的insert来说,插入string更灵活。
其他函数及其说明见下表。

二、搜索字符串


需要注意的有两点:
- 搜索函数返回类型为string::size_type,为无符号整数类型。
- 搜索失败时,返回string::npos,该值为-1,也就是无符号整数最大的值。
三、正则表达式库
正则表达式是字符串匹配的有力工具。C++11加入了对正则表达式的支持,具体定义位于
在C++中,正则表达式可以做的工作有:
- Match 将整个输入拿来比对(匹配)某个正则表达式
- Search 查找与正则表达式吻合的子串
- Tokenize 根据正则表达式切分字符串
- Replace 根据正则表达式替换字符串
第一种应用:Match和Search
具体流程可概括为:定义、匹配、判断
regex reg("<.*>.*</.*>"); // 定义
regex reg_num(R"(\d)"); // 以 R"(...)" 的方式定义,相当于 Python 中的 r"..." ,特点是内部反斜杠不需要写两遍
regex reg(R"(\S+)", regex::icase); // icase 表示忽略大小写
bool isExist = regex_match(string, reg); // 匹配整体,全部匹配则返回 true,注意参数顺序
//or
bool isExist = regex_search(string, reg); // 匹配部分,存在子串匹配则返回 true。注意参数顺序
cout << boolalpha << isExist << endl; // 判断,boolalpha 为 cout 的参数,表示将 bool 变量按照 true/false 输出而不是输出 0 和 1
你可能已经注意到了,regex_match和regex_search返回的仅仅是一个bool值,表明是否匹配。我们还需要匹配的位置。此时我们需要一个match对象来保存结果。
需要提取结果的场合,我们使用regex_search()和regex_match()的另一个版本,参数多了一个 match,运行完毕后 match 会保存有结果。
match对象的方法如下所示。
smatch m;
bool isExist = regex_search(string, m, reg); // 结果保存在m中
m.empty()
m.size() // 返回匹配个数
m.str(i) // 类似于python中group,返回第i个匹配位置的字符串。i=0则返回全部
m.length(i) // 同上,返回第i个匹配字符串的长度
m.position(i) // 同上,返回第i个匹配字符串的位置
m.prefix().str() // 已匹配位置之前的字符串,字符串前缀
m.suffix().str() // 已匹配位置之后的字符串,字符串后缀
for (auto pos = m.begin(); pos != m.end(); ++pos) {
cout << *pos << endl;
}
代码中的参数i,代表了正则表达式中存在分组,i为提取分组i的被匹配内容。类似python中的group。分组操作是正则表达式的语法,本文不再赘述。
match对象根据保存内容类型不同分成
smatch匹配stringcmatch匹配C风格字符串wsmatch匹配wstringwcmatch匹配const wchar_t*
第二种应用:Regex Iterator
data可能很长,reg可能会多次匹配。为了迭代所有的匹配子串,我们可以使用regex_iterator。
根据类型不同,分别是
sregex_iteratorcregex_iteratorwsregex_iteratorwcregex_iterator
regex reg("...");
sregex_iterator pos(data.cbegin(), data.cend(), reg);
sregex_iterator end; // 空迭代器即可表示 end
for (; pos != end; ++pos) {
cout << pos->str() << endl;
}
如何统计匹配个数?可以借助distance()来计算两个迭代器之间的距离。
比如要统计一句话中单词的个数:
regex reg(R"(\S+)");
string text = "The cat sat on the mat";
sregex_iterator begin{text.cbegin(), text.cend(), reg};
sregex_iterator end;
#include <iterator>
auto count = std::distance(begin, end); // 专门计算迭代器之间的距离
cout << count << endl; // output: 6
第三种应用:Regex Token Iterator
你可能关注的不是被匹配的字符串,而是其余的字符串。此时正则表达式串就像是切割刀一样,将data分割成不含被匹配串的几部分。我们可以利用此功能实现C++中一直没能实现的字符串分割函数split。
string data = "qqq www eee rrr";
regex r("\\s+");
sregex_token_iterator pos(data.cbegin(), data.cend(), r, -1); // -1代表你对正则表达式匹配的内容不感兴趣
sregex_token_iterator end;
for (; pos != end; ++pos) {
cout << *pos << endl;
}
第四种应用:替换
下面的代码将
<person><first>Nico</first></person>
替换成
<person><first value="Nico"/></person>
string data = "<person><first>Nico</first></person>"
regex reg("<(.*)>(.*)</(\\1)>");
string replace_pattern = "<$1 value=\"$2\"/>";
cout << regex_replace(data, reg, replace_pattern) << endl;
模式替换串用$n指定第几个匹配部分group(n)
$1 value=$2 含义即为原来是group(1)的部分替换成group(2)的内容。

四、string_view
C++17加入了string_view对象,能够避免string类型的复制临时对象操作。
- string_view对象由两部分组成,分别是数据的起始指针和数据的长度。有点类似于带其他语言表示字符串的方法,不依赖
'\0'在结尾,而是通过一个变量记忆长度。 - string_view只读,不能修改。可以很好地作为函数的参数和返回值
//使用string的拷贝操作
string s(1000, '0');
string sub_s = s.substr(100, 200); // O(n)
//使用view则不需要拷贝
string_view sv(s); // no copy
string_view sv2 = sv.substr(100, 200); // O(1)