本文最后更新于:星期二, 八月 2日 2022, 9:32 晚上
1. 利用朴素贝叶斯模型进行文本分类
朴素贝叶斯是一种构建分类器的简单方法。该分类器模型会给问题实例分配用特征值表示的类标签,类标签取自有限集合。它不是训练这种分类器的单一算法,而是一系列基于相同原理的算法:所有朴素贝叶斯分类器都假定样本每个特征与其他特征都不相关。
举个例子,如果一种水果其具有红,圆,直径大概3英寸等特征,该水果可以被判定为是苹果。尽管这些特征相互依赖或者有些特征由其他特征决定,然而朴素贝叶斯分类器认为这些属性在判定该水果是否为苹果的概率分布上独立的。
尽管是带着这些朴素思想和过于简单化的假设,但朴素贝叶斯分类器在很多复杂的现实情形中仍能够获取相当好的效果。2004年,一篇分析贝叶斯分类器问题的文章揭示了朴素贝叶斯分类器获取看上去不可思议的分类效果的若干理论上的原因。尽管如此,2006年有一篇文章详细比较了各种分类方法,发现更新的方法(如决策树和随机森林)的性能超过了贝叶斯分类器。
对于某些类型的概率模型,在监督式学习的样本集中能获取得非常好的分类效果。在许多实际应用中,朴素贝叶斯模型参数估计使用最大似然估计方法;换而言之,在不用到贝叶斯概率或者任何贝叶斯模型的情况下,朴素贝叶斯模型也能奏效。
朴素贝叶斯分类器的一个优势在于只需要根据少量的训练数据估计出必要的参数(变量的均值和方差)。由于变量独立假设,只需要估计各个变量的方法,而不需要确定整个协方差矩阵。
朴素贝叶斯分类器是与线性模型非常相似的一种分类器,但它的训练速度往往更快。这种高效率所付出的代价是,朴素贝叶斯模型的泛化能力要比线性分类器(如LogisticRegression 和LinearSVC)稍差。
朴素贝叶斯模型如此高效的原因在于,它通过单独查看每个特征来学习参数,并从每个特征中收集简单的类别统计数据。scikit-learn 中实现了三种朴素贝叶斯分类器:GaussianNB、BernoulliNB 和MultinomialNB。GaussianNB 可应用于任意连续数据, 而BernoulliNB 假定输入数据为二分类数据,MultinomialNB 假定输入数据为计数数据(即每个特征代表某个对象的整数计数,比如一个单词在句子里出现的次数)。BernoulliNB 和MultinomialNB 主要用于文本数据分类。
# 从sklearn.datasets里导入20类新闻文本数据抓取器。
from sklearn.datasets import fetch_20newsgroups
# 从互联网上即时下载新闻样本,subset='all'参数代表下载全部近2万条文本存储在变量news中。
news = fetch_20newsgroups(subset='all')
# 从sklearn.cross_validation导入train_test_split模块用于分割数据集。
from sklearn.cross_validation import train_test_split
# 对news中的数据data进行分割,25%的文本用作测试集;75%作为训练集。
X_train, X_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25, random_state=33)
# 从sklearn.feature_extraction.text里导入CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
# 采用默认的配置对CountVectorizer进行初始化(默认配置不去除英文停用词),并且赋值给变量count_vec。
count_vec = CountVectorizer()
# 只使用词频统计的方式将原始训练和测试文本转化为特征向量。
#学习词汇的词典并返回文档矩阵。
X_count_train = count_vec.fit_transform(X_train)
#不进行学习直接转换文档document-term矩阵
X_count_test = count_vec.transform(X_test)
# 从sklearn.naive_bayes里导入朴素贝叶斯分类器。
from sklearn.naive_bayes import MultinomialNB
# 使用默认的配置对分类器进行初始化。
mnb_count = MultinomialNB()
# 使用朴素贝叶斯分类器,对CountVectorizer(不去除停用词)后的训练样本进行参数学习。
mnb_count.fit(X_count_train, y_train)
# 输出模型准确性结果。
print ('The accuracy of classifying 20newsgroups using Naive Bayes (CountVectorizer without filtering stopwords):', mnb_count.score(X_count_test, y_test))
# 将分类预测的结果存储在变量y_count_predict中。
y_count_predict = mnb_count.predict(X_count_test)
# 从sklearn.metrics 导入 classification_report。
from sklearn.metrics import classification_report
# 输出更加详细的其他评价分类性能的指标。
print (classification_report(y_test, y_count_predict, target_names = news.target_names))
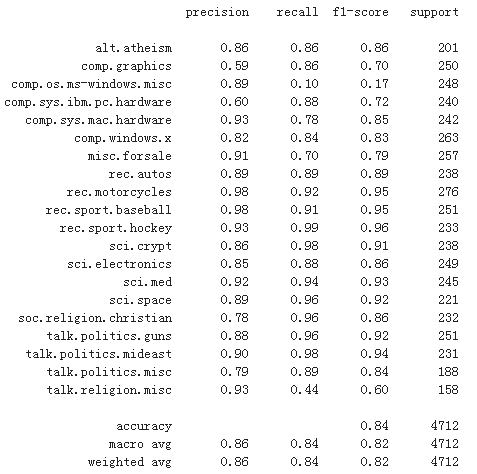
2. 利用SVM模型进行文本分类
3. pLSA、共轭先验分布、LDA
常用于文本数据的一种特殊技术是主题建模(topic modeling),这是描述将每个文档分配给一个或多个主题的任务(通常是无监督的)的概括性术语。这方面一个很好的例子是新闻数据,它们可以被分为“政治”“体育”“金融”等主题。如果为每个文档分配一个主题,那么这是一个文档聚类任务。如果每个文档可以有多个主题,那么这个任务与第3 章中的分解方法有关。我们学到的每个成分对应于一个主题,文档表示中的成分系数告诉我们这个文档与该主题的相关性强弱。通常来说,人们在谈论主题建模时,他们指的是一种叫作隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)的特定分解方法
隐含狄利克雷分布
从直观上来看,LDA 模型试图找出频繁共同出现的单词群组(即主题)。LDA 还要求,每个文档可以被理解为主题子集的“混合”。重要的是要理解,机器学习模型所谓的“主题”可能不是我们通常在日常对话中所说的主题,而是更类似于 PCA 或 NMF所提取的成分,它可能具有语义,也可能没有。即使 LDA“主题”具有语义,它可能也不是我们通常所说的主题。
举个自然语言处理的例子,我们可能有许多关于体育、政治和金融的文章,由两位作者所写。在一篇政治文章中,我们预计可能会看 到“州长”“投票”“党派”等词语,而在一篇体育文章中,我们预计可能会看到类似“队 伍”“得分”和“赛季”之类的词语。这两组词语可能会同时出现,而例如“队伍”和 “州长”就不太可能同时出现。但是,这并不是我们预计可能同时出现的唯一的单词群组。这两位记者可能偏爱不同的短语或者选择不同的单词。可能其中一人喜欢使用“划界”(demarcate)这个词,而另一人喜欢使用“两极分化”(polarize)这个词。其他“主题”可 能是“记者 A 常用的词语”和“记者 B 常用的词语”,虽然这并不是通常意义上的主题。
4. 使用LDA生成主题特征,在之前特征的基础上加入主题特征进行文本分类
参考文献
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!