本文最后更新于:星期二, 八月 2日 2022, 9:32 晚上
1. TF-IDF原理。
tf-idf(英语:term frequency–inverse document frequency)是一种用于信息检索与文本挖掘的常用加权技术。tf-idf是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。tf-idf加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了tf-idf以外,互联网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜索结果中出现的顺序。
原理
在一份给定的文件里,词频(term frequency,tf)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)对于在某一特定文件里的词语 ${\displaystyle t_{i}!}$来说,它的重要性可表示为:
以上式子中 ${\displaystyle n{i,j}!} n{i,j}$是该词在文件 ${\displaystyle d{j}!} d{j}$中的出现次数,而分母则是在文件 ${\displaystyle d{j}!} d{j}$中所有字词的出现次数之和。
逆向文件频率(inverse document frequency,idf)是一个词语普遍重要性的度量。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到:
其中
$|D|$:语料库中的文件总数
然后
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的tf-idf。因此,tf-idf倾向于过滤掉常见的词语,保留重要的词语。
1.2 例子
有很多不同的数学公式可以用来计算tf-idf。这边的例子以上述的数学公式来计算。词频(tf)是一词语出现的次数除以该文件的总词语数。假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是3/100=0.03。而计算文件频率(IDF)的方法是以文件集的文件总数,除以出现“母牛”一词的文件数。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是lg(10,000,000 / 1,000)=4。最后的tf-idf的分数为0.03 * 4=0.12。
1.3 tf-idf的理论依据及不足
tf-idf算法是创建在这样一个假设之上的:对区别文档最有意义的词语应该是那些在文档中出现频率高,而在整个文档集合的其他文档中出现频率少的词语,所以如果特征空间坐标系取tf词频作为测度,就可以体现同类文本的特点。另外考虑到单词区别不同类别的能力,tf-idf法认为一个单词出现的文本频数越小,它区别不同类别文本的能力就越大。因此引入了逆文本频度idf的概念,以tf和idf的乘积作为特征空间坐标系的取值测度,并用它完成对权值tf的调整,调整权值的目的在于突出重要单词,抑制次要单词。但是在本质上idf是一种试图抑制噪声的加权,并且单纯地认为文本频率小的单词就越重要,文本频率大的单词就越无用,显然这并不是完全正确的。idf的简单结构并不能有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能,所以tf-idf法的精度并不是很高。
此外,在tf-idf算法中并没有体现出单词的位置信息,对于Web文档而言,权重的计算方法应该体现出HTML的结构特征。特征词在不同的标记符中对文章内容的反映程度不同,其权重的计算方法也应不同。因此应该对于处于网页不同位置的特征词分别赋予不同的系数,然后乘以特征词的词频,以提高文本表示的效果。
2. 文本矩阵化,使用词袋模型,以TF-IDF特征值为权重。
TfidfVectorizer可以把原始文本转化为tf-idf的特征矩阵,从而为后续的文本相似度计算,主题模型(如LSI),文本搜索排序等一系列应用奠定基础。基本应用如:
第一步:分词
采用著名的中文分词库jieba进行分词:
import jieba
text = """我是一条天狗呀!
我把月来吞了,
我把日来吞了,
我把一切的星球来吞了,
我把全宇宙来吞了。
我便是我了!"""
sentences = text.split()
sent_words = [list(jieba.cut(sent0)) for sent0 in sentences]
document = [" ".join(sent0) for sent0 in sent_words]
print(document)
第二步:建模
理论上,现在得到的document的格式已经可以直接拿来训练了。让我们跑一下模型试试。
tfidf_model = TfidfVectorizer().fit(document)
print(tfidf_model.vocabulary_)
# {'一条': 1, '天狗': 4, '日来': 5, '一切': 0, '星球': 6, '全宇宙': 3, '便是': 2}
sparse_result = tfidf_model.transform(document)
print(sparse_result)
# (0, 4) 0.707106781187
# (0, 1) 0.707106781187
# (2, 5) 1.0
# (3, 6) 0.707106781187
# (3, 0) 0.707106781187
# (4, 3) 1.0
# (5, 2) 1.0
第三步:参数
查了一些资料以后,发现单字的问题是token_pattern这个参数搞的鬼。它的默认值只匹配长度≥2的单词,就像其实开头的例子中的'I'也被忽略了一样,一般来说,长度为1的单词在英文中一般是无足轻重的,但在中文里,就可能有一些很重要的单字词,所以修改如下:
tfidf_model2 = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b").fit(document)
print(tfidf_model2.vocabulary_)
# {'我': 8, '是': 12, '一条': 1, '天狗': 7, '呀': 6, '把': 9, '月': 13, '来': 14, '吞': 5, '了': 2, '日来': 10, '一切': 0, '的': 15, '星球': 11, '全宇宙': 4, '便是': 3}
token_pattern这个参数使用正则表达式来分词,其默认参数为r”(?u)\b\w\w+\b”,其中的两个\w决定了其匹配长度至少为2的单词,所以这边减到1个。对这个参数进行更多修改,可以满足其他要求,比如这里依然没有得到标点符号,在此不详解了。
3. 互信息
在概率论和信息论中,两个随机变量的互信息(Mutual Information,简称MI)或转移信息(transinformation)是变量间相互依赖性的量度。不同于相关系数,互信息并不局限于实值随机变量,它更加一般且决定着联合分布$ p(X,Y) $和分解的边缘分布的乘积$ p(X)p(Y) $的相似程度。互信息是点间互信息(PMI)的期望值。互信息最常用的单位是bit。
一般地,两个离散随机变量$ X $和$ Y $的互信息可以定义为:
其中$ p(x,y) $是 $X $和 $Y $的联合概率分布函数,而 ${\displaystyle p(x)} $和$ {\displaystyle p(y)} $分别是 X 和 Y 的边缘概率分布函数。
在连续随机变量的情形下,求和被替换成了二重定积分:
此外,互信息是非负的(即 $I(X;Y) ≥ 0$; 见下文),而且是对称的(即 $I(X;Y) = I(Y;X)$)。
互信息又可以等价地表示成
其中$ {\displaystyle \ H(X)} $ 和$ {\displaystyle \ H(Y)} $是边缘熵,$H(X|Y) $和$ H(Y|X) $是条件熵,而 $H(X,Y) $是 X 和 Y 的联合熵。
互信息越小,两个来自不同事件空间的随机变量彼此之间的关系性越低; 互信息越高,关系性则越高。
4. 对特征矩阵使用互信息进行特征筛选
sklearn.metrics.mutual_info_score
from sklearn import datasets
from sklearn import metrics as mr
iris = datasets.load_iris()
x = iris.data
label = iris.target
x0 = x[:, 0]
x1 = x[:, 1]
x2 = x[:, 2]
x3 = x[:, 3]
# 计算各特征与label的互信息
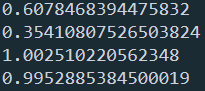
print(mr.mutual_info_score(x0, label))
print(mr.mutual_info_score(x1, label))
print(mr.mutual_info_score(x2, label))
print(mr.mutual_info_score(x3, label))
sklearn.feature_selection.mutual_info_classif
from sklearn import datasets
from sklearn.feature_selection import mutual_info_classif
iris = datasets.load_iris()
x = iris.data
label = iris.target
mutual_info = mutual_info_classif(x, label, discrete_features= False)
print(mutual_info)

参考文献
https://zh.wikipedia.org/wiki/Tf-idf
https://zh.wikipedia.org/wiki/%E4%BA%92%E4%BF%A1%E6%81%AF
https://blog.csdn.net/yyy430/article/details/88249709
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!