本文最后更新于:星期二, 八月 2日 2022, 9:32 晚上
1. Supervised learning
机器学习,机器从数据中学习固定的问题-答案模式,形成固定的问答模型的过程。
机器学习的过程可用下图表示:
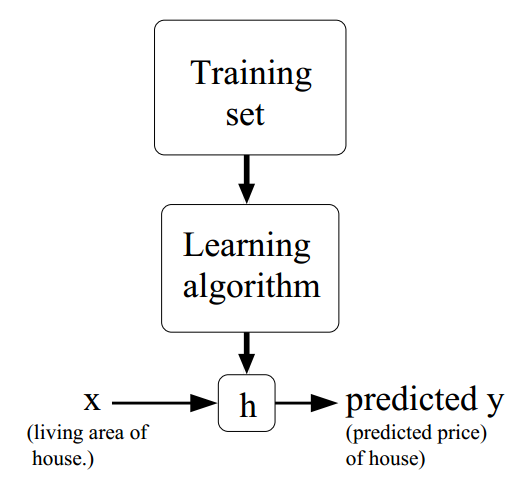
机器通过特定的学习方法Learning Algorithm学习已知的问题-答案数据集Training Set,Learning Algorithm最终会得到一个与真实模型相差无几的假说模型hypothesis。得到该模型之后,我们就可以利用它,对全新的问题的答案作出预测。
机器通过问题-答案训练模型的过程,称之为监督学习过程。问题是由一组已知数据构成的输入,比如房屋的面积、照射率、卧室数目等等;答案则是一个确切的结论,比如房屋的价格。刚才举的例子就是依照房屋的面积和其他信息来预测房屋的价格,输出值是一个实数(连续变量)。这在统计学上称之为回归问题。假设房屋的价格和面积成正比,则称上个问题为线性回归问题。
好了,那么机器怎么实现学习的呢?我们可以以预测房屋价格为例,构建一个学习模型。
首先,回归问题的本质就是通过给定一系列的参数,拟合出一个函数h(x),这个函数应该与真实函数y(x)越接近越好。h(x)大概长成这样:
今后为了方便起见,$\vec x$和$\vec \theta$等等就不加上箭头了,他们都表示由许多分量的向量。
可以看到,学习效果的好坏,取决于$\theta$选择的好坏,选择的好了$h_{\theta}(x)$就更逼近真实的y。学习的过程,就是不断修改$\theta$的过程。
那我们怎么改$\theta$呢?回想我们的数学建模过程,我们可以构造一个函数,自变量为$\theta$,检验y(x)与h(x)的距离(即差值),距离越小则说明$\theta$越完美。这不就转化成了一个最优化问题了吗?如果构造出来的函数还能够求导的话,求一次导,找到最低点,岂不是美滋滋?因此我们构造出来了以下函数:
其中m是样本个数,以上就是线性回归问题的损失函数,损失函数越小,训练得越好。
2. 求解损失函数最小值的迭代思路
按理说,我们直接对损失函数求导,马上就知道二次函数的最低点了。求这个函数的导数可不太容易,首先我们以非解析方法来迭代求解该函数。我们采用梯度下降法,逐步逼近全局最优点:
$\theta$维度太多,求导是个困难的事情。如果对$\theta$求梯度,得到某一点处下降速度最快的方向,即可逐步实现优化。下面是对$J(\theta)$求偏导数的过程:
因此我们得到了以下学习算法:
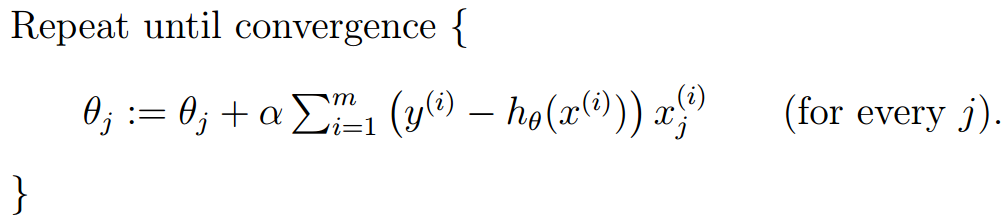
该算法具有“离终点越近,收敛速度越慢”的特点。该算法还有一个特点,即每计算一个$\theta$的分量$\theta_j$,算法都需要遍历一遍整个数据集。效率是O(n*n*m*k),n是维度,m是数据集大小,k是直到收敛为止循环的次数。
因为每判断一次,都需要整批数据的支持,因此这种梯度下降方式又称之为批梯度下降(batch gradient descent)。
做一个不恰当的比喻:批梯度下降好比每做一次选择,总是要询问周边所有的人的意见,之后给出一个让所有人都比较满意的方向。
与之相对应,如果我只问一个人的意见,就给出结论,这不就节约了遍历整个数据集的时间了吗?这种方法叫做随机梯度下降(stochastic gradient descent)。
算法表示如下:
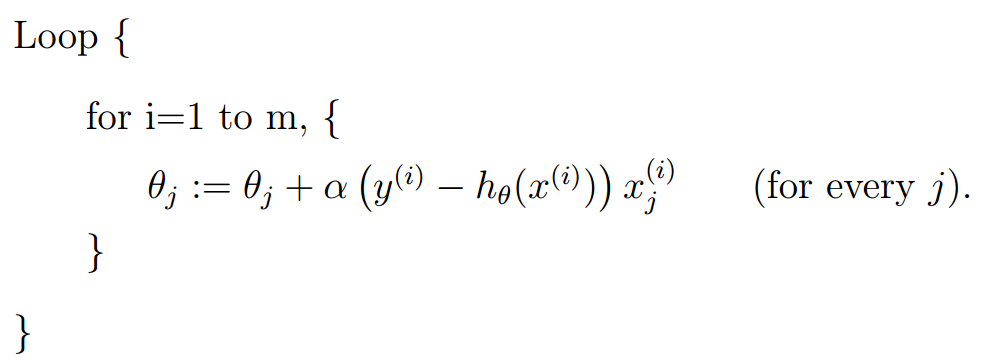
该算法的效率是O(n\n\k)。虽然性能得到了提升,但是牺牲了一部分准确性。事实证明随机梯度下降能在一定程度上代替批梯度下降,我们更多地使用小批量梯度下降法,即结合二者的优势,做决定之前问问一部分人的意见即可。
3. 求解损失函数最小值的代数证明
前文说过,对$J(\theta)$求导不是不行,而是因为如果$\theta$维度变高,求导相对困难。下面我们就来硬肛这个方法。
先要做一些数学知识铺垫,即矩阵的求导运算:
- 函数对矩阵求导
对于一个函数$f:\mathbb{R}^{m\times n}\mapsto\mathbb{R}$,即输入一个矩阵,输出一个值的此类函数,定义f对矩阵A求导(the derivative of f with respect to A)为:
举个例子,若定义$A=\left[ \begin{array}{ll}{A{11}} & {A{12}} \ {A{21}} & {A{22}}\end{array}\right]$,$f(A)=\frac{3}{2} A{11}+5 A{12}^{2}+A{21} A{22}$,那么有$\nabla{A} f(A)=\left[ \begin{array}{cc}{\frac{3}{2}} & {10 A{12}} \ {A{22}} & {A{21}}\end{array}\right]$。
- 矩阵的迹(trace, tr)
矩阵的迹特指方阵的迹。矩阵的迹就是上文所定义的函数f的一个代表。定义如下:
矩阵的迹有以下性质:
$tr(AB)=tr(BA)\
tr(ABC)=tr(CAB)=tr(BCA)\
tr(ABCD)=tr(DABC)=tr(CDAB)=tr(BCDA)\
trA=trA^T\
tr(A+B)=trA+trB\
traA=atrA$
矩阵的转置的性质:
$(AB)^T= B^TA^T \
(A+B)^T=A^T+B^T$
对迹求导的几个结论:
$\begin{aligned} \nabla{A} \operatorname{tr} A B &=B^{T} \ \nabla{A^{T}} f(A) &=\left(\nabla{A} f(A)\right)^{T} \ \nabla{A} \operatorname{tr} A B A^{T} C &=C A B+C^{T} A B^{T} \ \nabla_{A}|A| &=|A|\left(A^{-1}\right)^{T} \end{aligned}$
- 一些符号的定义
如果X是由样本构成的矩阵,y是由真实结果组成的向量,
由于$h_{\theta}\left(x^{(i)}\right)=\left(x^{(i)}\right)^{T} \theta$,所以我们可以得到下式:
=\left[ \begin{array}{c}{h{\theta}\left(x^{(1)}\right)-y^{(1)}} \ {\vdots} \ {h{\theta}\left(x^{(m)}\right)-y^{(m)}}\end{array}\right]
\begin{aligned} \frac{1}{2}(X \theta-\vec{y})^{T}(X \theta-\vec{y}) &=\frac{1}{2} \sum{i=1}^{m}\left(h{\theta}\left(x^{(i)}\right)-y^{(i)}\right)^{2} \ &=J(\theta) \end{aligned}
\begin{aligned} \nabla{\theta} J(\theta) &=\nabla{\theta} \frac{1}{2}(X \theta-\vec{y})^{T}(X \theta-\vec{y}) \ &=\frac{1}{2} \nabla{\theta}\left(\theta^{T} X^{T} X \theta-\theta^{T} X^{T} \vec{y}-\vec{y}^{T} X \theta+\vec{y}^{T} \vec{y}\right) \ &=\frac{1}{2} \nabla{\theta} \operatorname{tr}\left(\theta^{T} X^{T} X \theta-\theta^{T} X^{T} \vec{y}-\vec{y}^{T} X \theta+\vec{y}^{T} \vec{y}\right) \ &=\frac{1}{2} \nabla_{\theta}\left(\operatorname{tr} \theta^{T} X^{T} X \theta-2 \operatorname{tr} \vec{y}^{T} X \theta\right) \ &=\frac{1}{2}\left(X^{T} X \theta+X^{T} X \theta-2 X^{T} \vec{y}\right) \ &=X^{T} X \theta-X^{T} \vec{y} \end{aligned}
\theta=\left(X^{T} X\right)^{-1} X^{T} \vec{y}
y^{(i)}=\theta^{T} x^{(i)}+\epsilon^{(i)}
p\left(\epsilon^{(i)}\right)=\frac{1}{\sqrt{2 \pi} \sigma} \exp \left(-\frac{\left(\epsilon^{(i)}\right)^{2}}{2 \sigma^{2}}\right)
p\left(y^{(i)} | x^{(i)} ; \theta\right)=\frac{1}{\sqrt{2 \pi} \sigma} \exp \left(-\frac{\left(y^{(i)}-\theta^{T} x^{(i)}\right)^{2}}{2 \sigma^{2}}\right)
L(\theta)=L(\theta ; X, \vec{y})=p(\vec{y} | X ; \theta)
\begin{aligned} L(\theta) &=\prod{i=1}^{m} p\left(y^{(i)} | x^{(i)} ; \theta\right) \ &=\prod{i=1}^{m} \frac{1}{\sqrt{2 \pi} \sigma} \exp \left(-\frac{\left(y^{(i)}-\theta^{T} x^{(i)}\right)^{2}}{2 \sigma^{2}}\right) \end{aligned}
\begin{aligned} \ell(\theta) &=\log L(\theta) \ &=\log \prod{i=1}^{m} \frac{1}{\sqrt{2 \pi} \sigma} \exp \left(-\frac{\left(y^{(i)}-\theta^{T} x^{(i)}\right)^{2}}{2 \sigma^{2}}\right) \ &=\sum{i=1}^{m} \log \frac{1}{\sqrt{2 \pi} \sigma} \exp \left(-\frac{\left(y^{(i)}-\theta^{T} x^{(i)}\right)^{2}}{2 \sigma^{2}}\right) \ &=m \log \frac{1}{\sqrt{2 \pi} \sigma}-\frac{1}{\sigma^{2}} \cdot \frac{1}{2} \sum_{i=1}^{m}\left(y^{(i)}-\theta^{T} x^{(i)}\right)^{2} \end{aligned}
\frac{1}{2} \sum_{i=1}^{m}\left(y^{(i)}-\theta^{T} x^{(i)}\right)^{2}
其中$\tau$定义为带宽,我将会于近期更新文章解释局部加权回归。
6. 总结
我们介绍了机器学习中监督学习的概念,并引入了回归问题的解决方案,使用了最小二乘法对回归问题进行机器学习。对于最小二乘项,有两种方法可以对其优化,一种是逐步求精的梯度下降法,另一种则是一步到位的数学推导法。梯度下降适用于工程实现,而数学推导则是归纳总结背后的原理。
我们还从概率角度讨论了为什么回归问题要采用最小二乘法,并引入了欠拟合与过拟合的概念,最后采用局部加权回归方法尽可能避免拟合不良的问题。
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!